SVRNOS Governance Error Register
A classification system for AI platform governance failures, modeled on HTTP status codes. One hundred ten codes across seven architectural layers, with the TRACE Method practitioner workflow and two Dimension Markers.

Abstract
AI safety discourse has a vocabulary problem. Failure modes at the governance layer, the policies, escalation paths, audit systems, and human review processes that wrap AI models, are poorly named, inconsistently described, and not shared across the engineering, legal, policy, and research communities that need to communicate about the same events. The SVRNOS AI Governance Error Register (GER) is a structured classification system for AI platform governance failures. v0.1 introduced twenty-seven codes organized as HTTP-derived numeric mnemonics across five tiers.
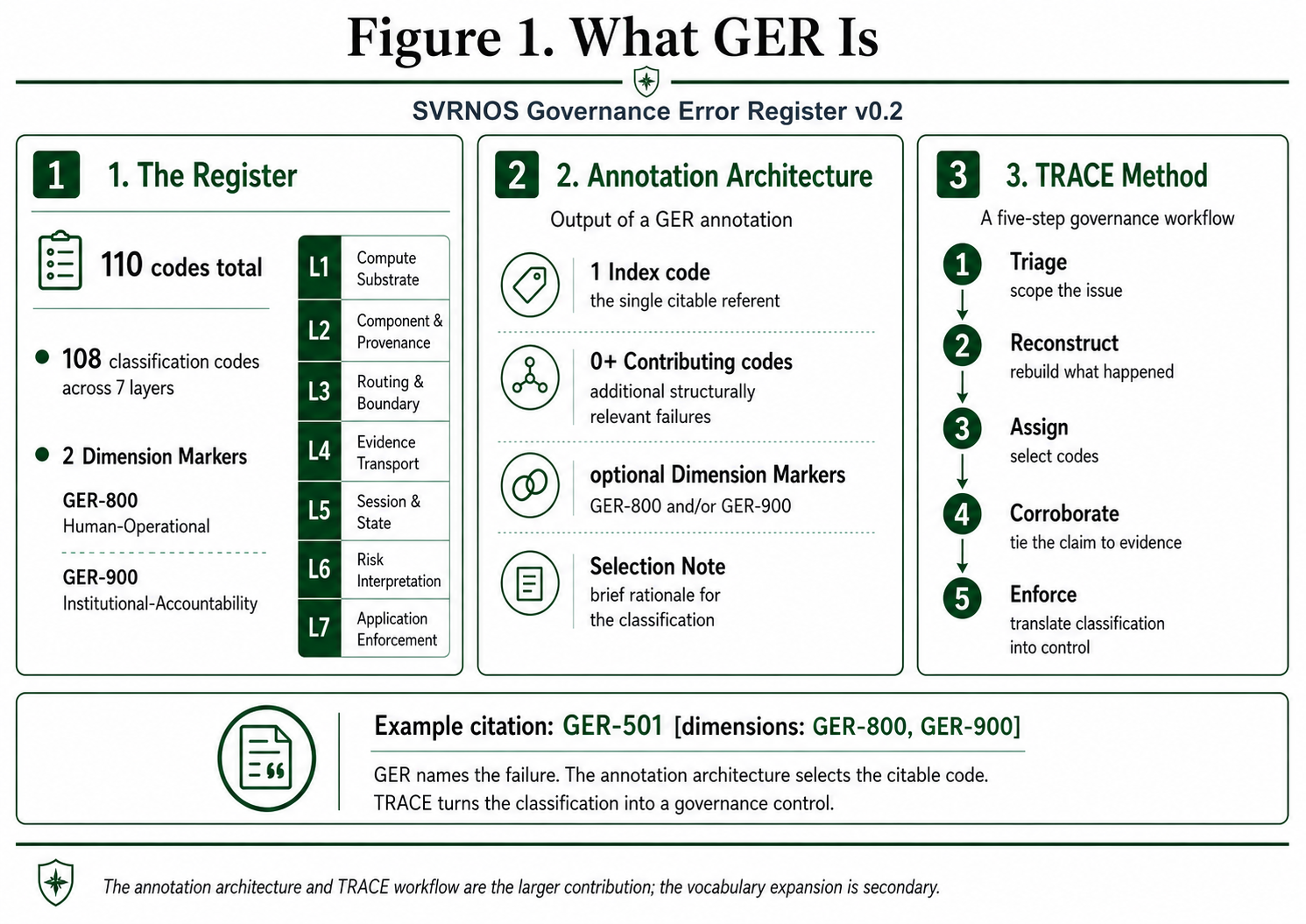
v0.2 makes three contributions. The first is the register itself: a one-hundred-ten-code taxonomy (one hundred eight L1–L7 classification codes plus two Dimension Markers, GER-800 Human-Operational Dimension and GER-900 Institutional-Accountability Dimension), with every classification code assigned to a layer in the SVRNOS 7-Layer Model. The second is an annotation architecture that produces a single Index Governance Failure code per incident, zero or more Contributing Governance Failure codes, and optional Dimension Markers, and a written Selection Note.
The third is the TRACE Method (Triage, Reconstruct, Assign, Corroborate, Enforce), a five-step practitioner workflow that applies the architecture to a public incident record and carries it through to the governance control that should now exist. The full register (110 codes) is maintained at docs.svrnos.com/ger and included as Appendix A; this paper presents the methodology, the framing, and a lean reading of the register through the 7-Layer Model. The annotation architecture and the TRACE workflow are the larger contribution; the vocabulary expansion is secondary.
Immediate Opportunities
| Stakeholder | What you can do with the GER |
|---|---|
| Regulators | Cite GER codes in enforcement disclosures, rulemaking notices, and incident reporting templates. Codes are free, open, and designed to carry a citable predicate into court. |
| Operators | Classify internal incident logs against the GER from day one. 24-hour and 72-hour disclosure obligations are easier to file and harder to challenge when the audit trail uses structured codes. |
| Insurers | Structure AI liability questionnaires and underwriting around GER codes. Operators filing structured GER classifications produce measurably different risk profiles than operators filing narratives. |
| Auditors & standards bodies | Reference the GER as the upstream classification layer when designing AI audit programs. Cross-citation with vertical-specific standards strengthens both. |
| Researchers & civil society | Use GER codes to describe and compare incidents across institutions, disciplines, and jurisdictions. Propose new codes when existing ones do not capture a failure you observe. |
| Educators & professors | Teach AI safety, governance, and Trust & Safety courses using the GER as the framework. Seven architectural layers, 110 codes, HTTP semantic mapping students already recognize. CC BY 4.0, free for coursework. |
| Journalists & reporters | Classify AI safety incidents with GER codes when reporting. Shared vocabulary makes coverage comparable across outlets and across incidents. A 501 in one newsroom is a 501 in another. |
Detailed asks and adoption pathway in Section 8, Adoption.
1. Introduction
On February 10, 2026, Jesse Van Rootselaar killed eight people in Tumbler Ridge, British Columbia, before killing herself. Months earlier, in June 2025, OpenAI had identified and banned a ChatGPT account belonging to Van Rootselaar after conversations involving violent scenarios with guns triggered automated review. Reporting later stated that some OpenAI employees urged leaders to alert Canadian law enforcement, but the company ultimately decided the activity did not meet its threshold for referral and did not notify authorities at the time.
In April 2026, seven families of victims injured or killed in the shooting filed lawsuits against OpenAI and Sam Altman in the United States District Court for the Northern District of California. Altman later apologized publicly: “I am deeply sorry that we did not alert law enforcement to the account that was banned in June.”
This is a story about a governance failure that has no agreed name.
Detection succeeded. The threat was real. The failure was a true positive with no downstream escalation handler. Detection fired and terminated at the platform boundary. The path to law enforcement was never built. Eight people died; the families’ lawsuits allege that gap is why.
This taxonomy calls that failure a 501, Escalation Not Implemented.
The naming is deliberate. HTTP status codes are the closest existing model for what the AI safety field needs: a numeric, shared vocabulary for structural failures in a running system. Engineers learn 404 and 500 before they write their first production service. Regulators, lawyers, and journalists understand 404 instinctively. The HTTP status-code pattern is familiar to most technical and Trust & Safety practitioners working around platform operations. Borrowing that vocabulary for governance failures is a precise mnemonic, not a one-to-one mapping: each GER code earns its place by preserving the operational shape of the corresponding HTTP status where possible, and extends the register only where governance failures require new distinctions.
The timing is not incidental. Oregon’s SB 1546, passed in April 2026 and effective January 1, 2027, is one of the first state-level AI companion chatbot reporting regimes. California’s Transparency in Frontier Artificial Intelligence Act (SB 53), signed September 29, 2025 and effective January 1, 2026, requires frontier developers to report critical safety incidents within 15 days, and within 24 hours when the incident poses an imminent risk of death or serious physical injury. New York’s RAISE Act (S. 6953-B), signed December 19, 2025 and effective ninety days after enactment, sets frontier developer obligations enforced by the New York Attorney General, including civil penalties of up to $10 million for a first violation and up to $30 million for any subsequent violation.
These regimes assume platforms have governance infrastructure to report on. Many do not. Tumbler Ridge 501 is the category default.
This taxonomy provides the vocabulary to name, classify, and communicate these failures across the disciplines, engineering, law, policy, safety research, that must work together to close them. v0.2 publishes the annotation protocol that turns a public AI incident into a citable classification: the TRACE Method.
2. Related Work
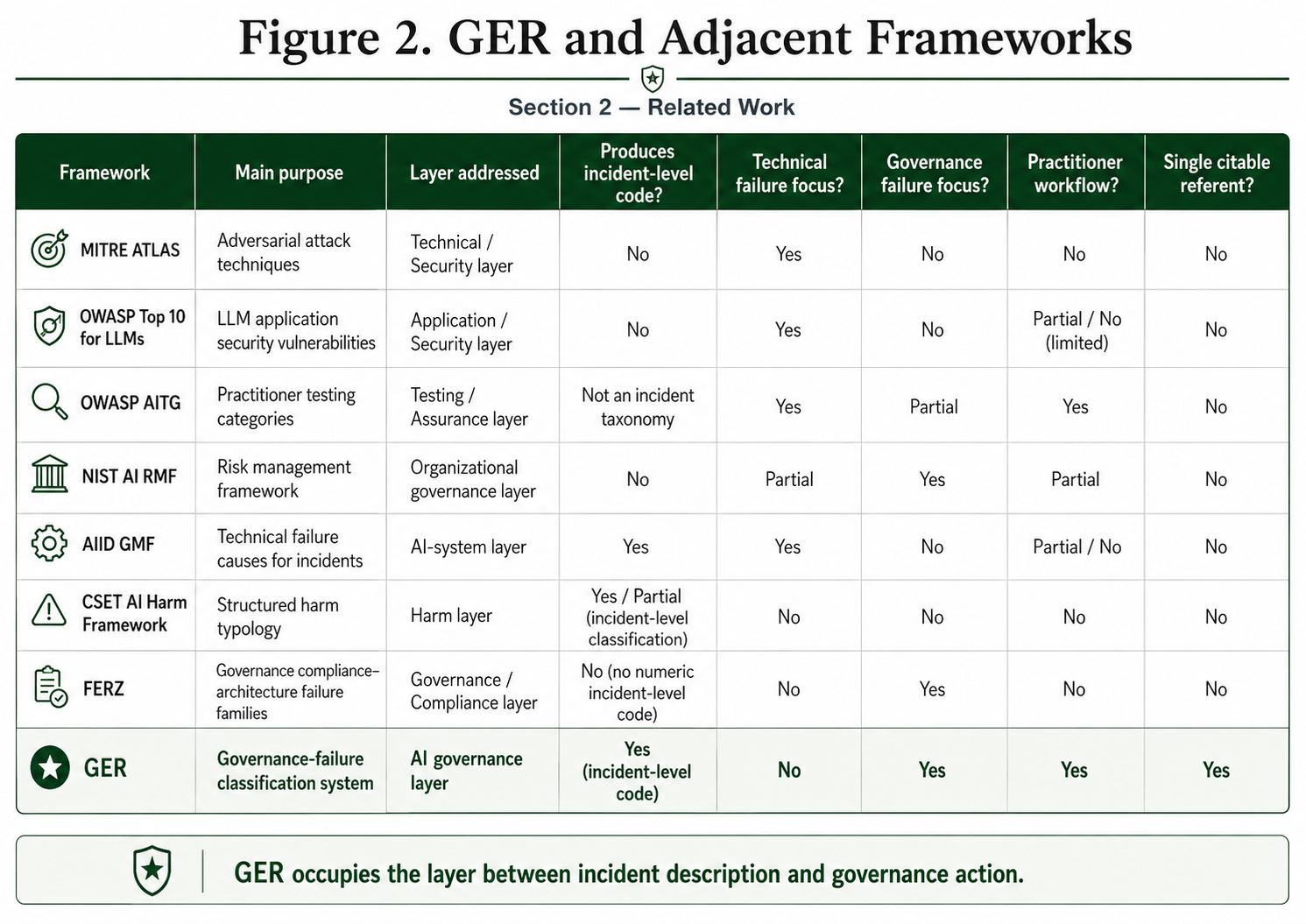
Several existing frameworks address adjacent problems, but none provides a citable, incident-level vocabulary for failures in the governance machinery specifically. This section positions GER among them.
MITRE ATLAS maps adversarial attack techniques against machine learning systems, modeled on the MITRE ATT&CK framework for cybersecurity. It is comprehensive on attack vectors, adversarial inputs, data poisoning, model evasion, but explicitly focused on technical and security failures, not governance failures. A platform that detects a threat and fails to escalate it has no ATLAS code.
OWASP Top 10 for LLMs catalogs the ten most critical security vulnerabilities in large language model applications, including prompt injection, insecure output handling, and training data poisoning. Like ATLAS, it addresses what attackers can do to models, not what platforms fail to do in governance.
OWASP AI Testing Guide (AITG) v1.0 publishes a structured set of practitioner test categories for AI systems, including data, prompt, output, behavioral, and adversarial dimensions. AITG names the test surface (what to test, how to test it, and what passing or failing each test means). GER names the governance-failure class invoked when a test fails (Matteo Meucci, project lead OWASP AI Testing Guide v1.0). The two are complementary: AITG describes the test; GER classifies the failure. NCSA (Non-Content Safety Attestation), an open companion specification, is a candidate machine-readable receipt for both.
OWASP Top 10 for Agentic Applications (2026) catalogs ten ranked-by-criticality threat categories specific to agentic AI (ASI01 Agent Goal Hijack, ASI02 Tool Misuse, ASI03 Identity & Privilege Abuse, ASI04 Agentic Supply Chain, ASI05 Unexpected Code Execution, ASI06 Memory & Context Poisoning, ASI07 Insecure Inter-Agent Communication, ASI08 Cascading Agent Failures, ASI09 / ASI10 Rogue Agents). Like the LLM Top 10 and ATLAS, it names threats and attacker actions, not governance failures. T8-style audit gaps in the companion document overlap GER-210 (Governed but Unlogged) and GER-211 (Missing Reconstructible Evidence) but from the attacker-repudiation angle rather than the governance-record angle.
OWASP Agentic AI – Threats and Mitigations v1.1 (December 2025) publishes seventeen agent-specific threat patterns (T1–T17) each paired with technical and procedural mitigations: memory poisoning, tool misuse, privilege compromise, resource overload, cascading hallucination attacks, intent breaking and goal manipulation, misaligned and deceptive behaviors, repudiation and untraceability, identity spoofing and impersonation, overwhelming human in the loop, unexpected RCE and code attacks, agent communication poisoning, rogue agents in multi-agent systems, human attacks on multi-agent systems, human manipulation, insecure inter-agent protocol abuse, and supply chain compromise. GER and the OWASP threat catalog are complementary per incident: OWASP names what an attacker did or could do; GER classifies what governance failed to do.
OWASP Multi-Agentic System Threat Modeling Guide v1.0 (MAESTRO) introduces a seven-layer threat-modeling methodology (Foundation Model · Data Operations · Agent Framework · Deployment Infrastructure · Evaluation & Observability · Security & Compliance · Agent Ecosystem) crossed with four agentic factors (Non-Determinism, Autonomy, Identity Management, Agent-to-Agent Communication). MAESTRO and the SVRNOS 7-Layer Model are both OSI-inspired seven-layer decompositions, but on orthogonal axes: MAESTRO maps where threats originate for security teams; SVRNOS 7L maps where governance fires or fails to fire. The two compose per incident — a MAESTRO threat-modeling exercise can identify a structural exposure; a GER classification names the governance failure that allowed the exposure to manifest.
NIST AI Risk Management Framework (AI RMF 1.0) provides a voluntary framework organized around Govern, Map, Measure, and Manage functions. It is comprehensive at the institutional level, identifying categories of risk, recommending practices, and establishing organizational responsibilities. It does not produce named, citable codes for specific failure modes. NIST AI RMF can be cited as a risk-management framework, but it does not provide incident-level failure codes. GER is designed to supply that classification layer.
FERZ, “Governance Laundering: A Taxonomy of Failure Modes in AI Compliance Architectures” (February 2026) is the closest prior work. It presents a taxonomy of seven failure-mode families, governance laundering, policy theater, and five related categories, each defined by the structural property it violates. Its contribution is real: it is the first taxonomy that explicitly addresses the governance layer rather than the model or security layers. Its limitation is vocabulary: the seven categories use framework-specific names that do not map to existing technical mental models. A Trust & Safety engineer reading about “governance laundering” must learn a new framework from scratch. A Trust & Safety engineer reading about a 501 already understands the shape of the failure.
AI Incident Database (AIID) Goals/Methods/Failures (GMF) taxonomy (Pittaras and McGregor, SafeAI 2023) catalogs technical failure causes at the AI-system layer across the Responsible AI Collaborative’s incident corpus. GMF and GER are explicitly complementary: GMF describes the technical failure mode (hallucination, distributional bias, robustness gap); GER describes the governance failure that allowed the unverified technical behavior to reach a user or cause harm. A single incident is often cross-citable across both. The Index + Contributing architecture in v0.2 is partly modeled on the AIID GMF approach to multi-label classification.
OECD Common Reporting Framework for AI Incidents (OECD, 2025). Developed with GPAI, this framework distills 29 criteria across eight dimensions (incident metadata, harm details, affected people and planet, economic context, data and input, AI model, task and output, and submitter information) to standardize cross-jurisdictional incident reporting. The framework is descriptive by design: it captures what happened, what harm resulted, and what system was involved. It explicitly places information about causes outside its core criteria, as supplementary detail that “policymakers may wish to solicit from specific actors with privileged access” (OECD, 2025, p. 12).
GER supplies that missing layer: a citable vocabulary for the structural governance cause behind a reported incident. The two are interoperable rather than overlapping: a regulator implementing the OECD framework can attach a GER code to classify the governance failure behind an incident, extending a descriptive report into a structurally classified one.
CSET AI Harm Framework (Hoffmann and Frase, 2023) adds structured harm taxonomy to the AIID corpus and provides a parallel reference for cross-source validation. GER’s scope is governance-layer; CSET’s is harm-typology; the two combine cleanly per incident.
Responsibility and accountability mapping over the AIID corpus. A parallel line of work codes public AI incidents for who is responsible and how accountability unfolds, rather than for the governance control that failed. Hadan et al. (2025) analyze 202 AI privacy and ethical incidents to map lifecycle stage, contributing causes, responsible entities, disclosure sources, and impacts, finding that many harms trace to organizational decisions and legal non-compliance. Richards et al. (2025), in a three-tier analysis of 962 AIID incidents and 4,743 related reports, find that identifiable responsible parties do not reliably produce accountability and that social response is highly context-dependent. These works ask who answered for an incident and whether accountability followed; GER asks what structural control in the governance machinery was missing. The questions are complementary and combinable per incident, and GER does not attempt the responsibility attribution those works perform.
EA Forum, “Toward a Common Language for Human-AI Interaction Failures” (April 2026) proposes a 22-pattern taxonomy at the interaction layer, how users and AI systems miscommunicate in extended conversations. It explicitly positions itself as the missing third layer below governance (NIST) and architecture (Microsoft MAST). It is not prior art against this taxonomy; the layers are structurally distinct and non-overlapping.
Vertical-specific AI litigation databases are the legal-corpus counterpart to AIID’s general incident corpus, and GER is designed to apply across them. The Database of AI Litigation (DAIL), maintained by the Ethical Tech Initiative at George Washington University Law School, tracks AI-related litigation from complaint forward across hiring, credit, criminal sentencing, generative AI training, and AI companion liability. The Health Litigation Tracker at Georgetown University Law Center catalogs healthcare AI litigation specifically and has been used to identify patterns in patient harm from algorithmic determinations by insurers, hospitals, and state health agencies (Mansi & Riedl, 2025). The AI, Algorithmic, and Automation Incidents and Controversies Database (AIAAIC) catalogs algorithmic harm cases across sectors. The Charlotin AI Hallucinations in Court Cases database tracks lawyer-side AI misuse and judicial sanctions across global jurisdictions. Each database addresses a different layer of legal-AI accountability; GER is the structural failure-classification layer that can be applied across all of them. A single litigated AI incident may be cross-classifiable in multiple databases simultaneously, and GER provides the shared governance-failure vocabulary that allows comparison across legal verticals.
Legally-Informed Explainable AI and the patient-centered accountability frame. Mansi, Karusala, and Riedl (2025) identify a structural gap in current AI explainability work: AI accountability systems are designed for decision makers (e.g., physicians, claims reviewers), but the people actually harmed by AI determinations are decision subjects (e.g., patients, applicants) who lack the technical, legal, and institutional access to contest those determinations. Their analysis of 31 healthcare AI legal cases and reported harms finds that almost none involve malpractice claims against physicians; the dominant pattern is insurance companies and state systems using algorithms to override physicians’ decisions or deny medically necessary care, with patients left to seek legal recourse. GER’s 800 Human-Operational and 900 Institutional-Accountability dimension markers record this stakeholder asymmetry at the incident classification layer; the GER-315 Accountability Decoupling code names the “hot potato” pattern Mansi and Riedl observe; and the GER worked examples in this register (including healthcare AI insurance-denial cases such as Estate of Gene B. Lokken et al. v. UnitedHealth Group, Inc., classified under L7 with NaviHealth’s nH Predict as the upstream algorithmic actor) are intended to be jointly citable with their analysis to support the patient-centered accountability infrastructure they advocate.
This work targets a narrower representational gap not fully covered by existing incident, harm, and risk-management frameworks: a numeric, shared, HTTP-derived vocabulary for governance-layer failures, designed to be immediately legible to engineers, lawyers, regulators, and researchers without requiring framework-specific training, with a published annotation protocol that produces reproducible single-referent classifications from public incident records. GER is an addition to this ecology of incident taxonomies, not a replacement for it: it occupies the layer between incident description (what happened) and governance action (what control must now exist), and is designed to be cited alongside technical-cause, harm, and responsibility codings of the same incident.
3. Design Principles
3.1 Governance layer, not model layer. This taxonomy classifies failures of the safety infrastructure that wraps AI models, policies, escalation paths, audit systems, human review processes. Model hallucinations, capability limitations, and adversarial attacks are out of scope.
3.2 Signaling layer, not policy layer. Codes describe what failed. They do not define what platforms are required to do. A 404 means no matching rule was found in the active ruleset. It does not specify what rule should have existed. That is a regulatory and policy question this taxonomy deliberately does not answer.
3.3 Success states are defined. 200 and 204 establish what governed behavior looks like. A taxonomy of failures without a defined success state is a list of complaints, not a classification system.
3.4 HTTP mapping must be earned. Each code maps to its HTTP semantic directly and defensibly. The validation test: would a regulator understand immediately why this code maps to this failure? Codes that require explanation of the mapping are excluded. Extended codes are introduced only where no existing HTTP code maps cleanly.
3.5 The register is open and versioned. The taxonomy is v0.2. Codes are added, refined, or retired as the governance landscape evolves and real-world instances accumulate. Every emitted code in any implementation must carry a taxonomy_version field. Historical records are never retroactively reclassified.
3.6 Every classification code is assigned to a layer in the SVRNOS 7-Layer Model. Layer assignment is part of the code’s identity. The layer answers “where in the AI governance stack did this fail,” which the numeric tier alone does not. The 7-Layer Model is documented in the companion SVRNOS 7-Layer Model paper, published alongside this register; the seven layers are L1 Compute Substrate, L2 Component & Provenance, L3 Routing & Boundary, L4 Evidence Transport, L5 Session & State, L6 Risk Interpretation, L7 Application Enforcement.

3.7 Dimension Markers are non-Index-eligible. Two namespaces (800-series Human-Operational, 900-series Institutional-Accountability) exist outside the L1–L7 classification space. Dimension Markers describe the external control plane within which a structural AI governance failure occurred. They cannot stand alone, are excluded from Distinct-From pairs, and are reported in a separate prevalence series. The anti-blame-shifting rule (Section 6.3) is published as a constraint on their use.
3.8 Code addition follows a published admission discipline. New codes enter the register only after passing a ten-condition test (Section 4.5.2). The discipline is IANA-inspired: stable numeric identifiers, published definitions, reserved namespaces, change control, and expert editorial review. GER does not adopt vendor-claim conventions in which any party may unilaterally claim a numeric slot.
3.9 Tier names describe structural shape, not value. Each numeric tier names the structural shape of the event using its HTTP analog: 2xx Success States cover moment-level governance handling; 3xx Structural Moves cover deliberate platform-level changes to the product; 4xx Client/Operator Errors cover operator-side rule failures; 5xx Infrastructure Failures cover underlying-stack governance failures. Value judgments do not derive from tier. The 3xx Structural Moves tier contains both positive moves (GER-301 Risk Surface Retired, retiring a dangerous surface deliberately) and negative ones (GER-306 Safety Constraint Retired, GER-309 Compliant Harm, GER-310 Jurisdiction Evasion). A reader asking whether the outcome was good or bad needs the code’s documented intent, not its numeric tier.
4. Methodology
GER v0.2 adds two methodological layers to the v0.1 taxonomy. The first is the v0.1 taxonomy development process, retained for provenance. The second is a published annotation protocol for applying the taxonomy to real-world AI incidents. The annotation protocol is new in v0.2 and is the larger contribution.
4.1 Taxonomy development (v0.1 origin, retained)
The v0.1 taxonomy was developed through a structured multi-model synthesis process in April 2026, with the Tumbler Ridge litigation (February 2026) as the base case. The 501 code (Not Implemented) was established first: a platform detected a credible threat, executed an internal enforcement action, and had no escalation path to law enforcement because none was built. The HTTP semantic, “the handler that should have existed was never written,” was the structural fit.
The taxonomy prompt was submitted independently to four production LLMs (GPT-4o, Gemini, Llama, Grok), each given the 501 as a reference case and asked to map additional HTTP codes to structurally distinct AI governance failures under three constraints: each mapping had to survive the regulator test, each code had to describe a failure at the governance layer (not model or security), and Distinct-From boundaries had to be specified. Cross-model consensus codes were treated as higher-confidence; single-model proposals received additional regulator-test validation. The 205 code (Reset Content) was added during the process after a generation-then-suppression event was observed on one synthesis platform. The taxonomy grew from twenty to twenty-one codes during the synthesis process and reached twenty-seven codes in the v0.1 published release.
4.2 v0.2 expansion
The v0.2 vocabulary grew from twenty-seven to one hundred eight L1–L7 classification codes between April and May 2026, through four sources of addition. First, public AI incidents and published safety research reviewed during the period were tested against the existing vocabulary; failure modes with no clean home and not covered by a Distinct-From neighbor produced new codes after regulator-test validation. Second, contributors (acknowledged at the end of the paper) shaped specific codes through public LinkedIn exchanges, draft comment threads, and direct correspondence, ranging from canonical naming of previously unnamed failure modes to clarifying boundaries between adjacent codes.
Third, the SVRNOS 7-Layer Model was developed in parallel and assigns each code to a layer in an OSI-inspired AI governance stack; layer assignment supports the annotation protocol in 4.3. Fourth, a set of candidate codes was identified through structured multi-model synthesis and promoted to full status only after independent reproduction testing.
Two Dimension Markers were added during the same window: GER-800 Human-Operational Dimension and GER-900 Institutional-Accountability Dimension. The v0.2 vocabulary is one hundred ten codes total. The full register was also batch-tested against the AIID corpus to check coverage at scale.
Distinct-From binary pairs were authored across the one hundred eight L1–L7 classification codes. Each pair documents that two codes name structurally different failures and cannot co-apply to the same incident. The set of Distinct-From pairs operationalizes the discriminant-validity statement of the taxonomy. Dimension Markers are excluded from Distinct-From pairs by design (Section 6.1).
4.3 Annotation protocol
The v0.2 annotation protocol classifies a public AI incident under the GER vocabulary. The protocol is rule-constrained and designed to improve reproducibility. It is designed to produce reproducible classifications by a single annotator at v0.2 scale and to be extensible to community contributors at a later stage.
4.3.1 Architecture. Each incident is annotated with one Index Governance Failure code and zero or more Contributing Governance Failure codes. The Index code is the single citable referent. The Contributing set is the structural profile.
The Index + Contributing architecture is adapted from precedent in adjacent high-stakes domains. The U.S. ICD-10-CM coding system permits multiple diagnosis codes in a record while requiring a principal diagnosis for non-outpatient settings under an ordered ruleset (ICD-10-CM Official Guidelines, FY2026, Section II). The Medical Dictionary for Regulatory Activities (MedDRA) permits multi-axial placement of an adverse-event term (a Preferred Term can be represented in more than one System Organ Class) while assigning one primary System Organ Class “to avoid ‘double counting’ while retrieving information from all SOCs” in cumulative outputs (MedDRA Introductory Guide, Version 28.1, September 2025, Section 3.5, p. 10). The medical and pharmacovigilance systems provide the closest precedent for GER’s single-referent design.
Aviation occurrence classification (the CICTT framework used by the U.S. National Transportation Safety Board) provides a parallel precedent for preserving structured multi-factor incident information (CICTT v4.6, 2013).
The architecture distinguishes GER from two rejected alternatives. Single-code-per-incident classification is inconsistent with the multi-causal structure preserved by the mature systems reviewed. Pure multi-tag classification without a designated index code, the model used by MITRE ATT&CK, is analytically rich but does not produce a stable single referent for police investigators, journalists, lawyers, and regulators.
4.3.2 Candidate inclusion. A GER code enters the candidate set for an incident only if the incident record supports a clear structural match and the code is causally relevant. The standard is that the source either explicitly reports the failed control or its absence, or the failure can be strongly inferred from the described system behavior. “A control somewhere in the stack might have helped” is not enough.
This evidence-first inclusion rule is warranted by the source material. Public AI incident reports vary in technical depth and quality, contain errors and omissions, and reflect a fraction of underlying reality (OECD, 2025; MIT AI Incident Tracker; Paeth et al., 2024). Inclusion discipline at the front of the protocol prevents speculative coding from compounding through downstream steps.
4.3.3 Distinct-From exclusion. Distinct-From pairs are enforced as hard exclusions. If two candidate codes form a Distinct-From pair, they cannot co-apply to the same incident. The annotator must select the one the evidence actually supports and discard the other. Co-application of a Distinct-From pair is a rejected annotation, machine-checkable at publication.
The Distinct-From mechanism is the GER analog of the ICD-10-CM Excludes1 note (ICD-10-CM Official Guidelines, FY2026, Section I.A.12.a), one of the clearest drift-reduction devices in clinical coding because it is mechanically enforceable.
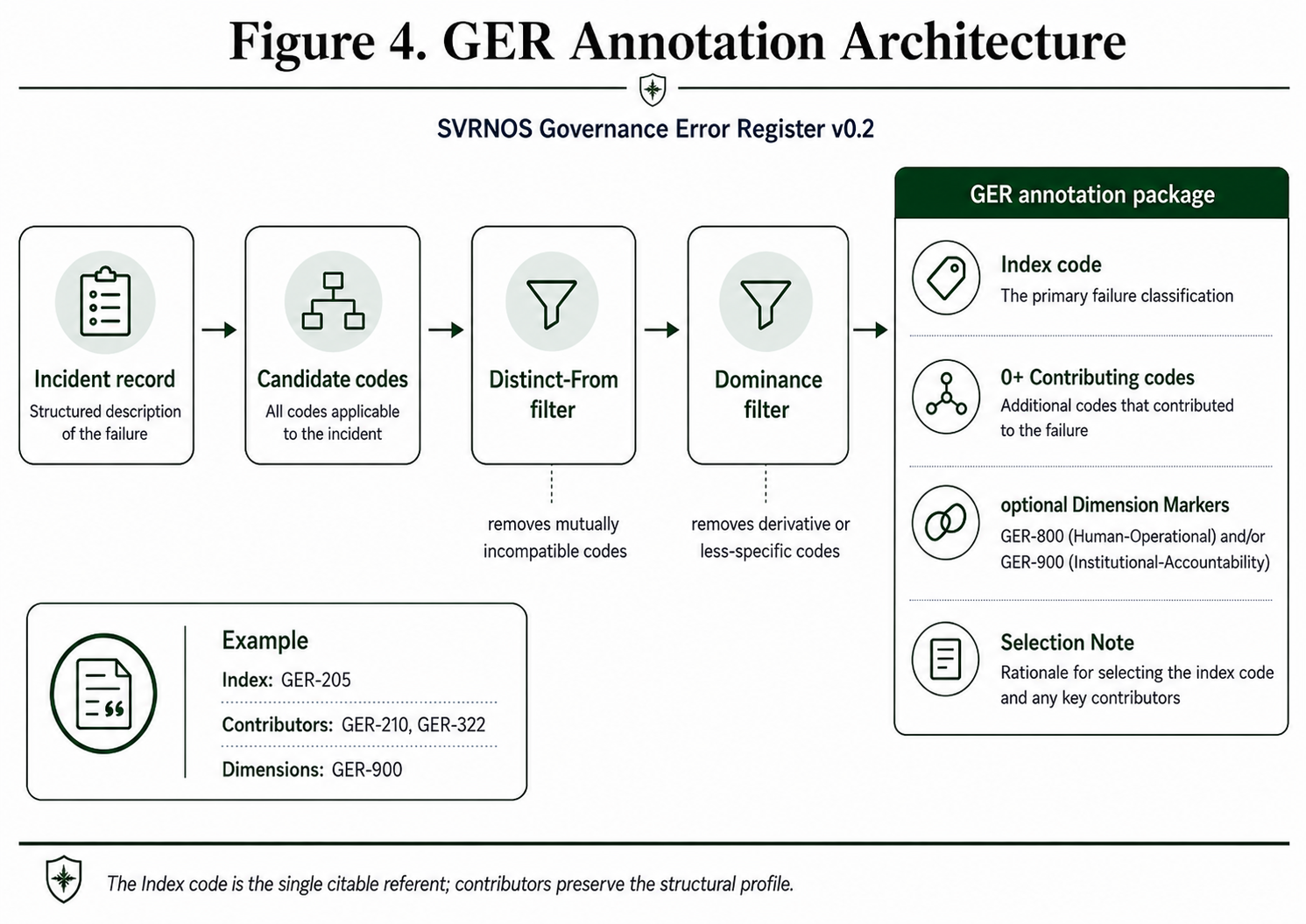
4.3.4 Dominance and non-redundancy. A separate rule table addresses dominance and non-redundancy. When one GER code fully captures the failure, the annotator does not double-code derivative manifestations or less-specific near-neighbors. The dominance rule is published alongside the Distinct-From table.
The dominance rule addresses a different drift source from Distinct-From. Distinct-From pairs catch mutual incompatibility between structurally different codes. The dominance rule catches over-coding: the inclusion of a derivative or less-specific code when a more specific or more upstream code already captures the failure. The rule is informed by ICD-10’s combination-code conventions, which collapse common multi-condition pairings into single codes to prevent over-coding (ICD-10-CM Official Guidelines, FY2026, Section I.A.5).
4.3.5 Index selection. After Distinct-From and dominance exclusions, one Index code is selected as the earliest sufficiently-evidenced structural failure that initiated the governance breakdown leading to the incident. The Index code names the structural initiating failure, not the downstream consequence or the most visible symptom.
The Index selection rule is adapted from underlying-cause conventions in two domains. WHO and CDC mortality coding selects the underlying cause of death by an initiating-chain rule rather than by visibility or proximate severity. MITRE CWE distinguishes primary weaknesses from resultant or chained weaknesses, and instructs mappers to identify the root cause rather than the downstream technical impact (MITRE CWE CVE-to-CWE Root Cause Mapping Guidance v1.1, 2024).
Three cascading tie-breakers resolve cases where multiple Index candidates remain after exclusion. First, when two candidates are at different layers in the 7-Layer Model and both are sufficiently evidenced, the candidate at the earlier layer is preferred. Second, if both candidates are at the same layer or evidence weight prevents layer-order resolution, the more specific code is preferred. Third, if specificity is equal, the lower numeric code is preferred. The third rule is a deterministic residual; a fixed ordering rule is preferred over open discretion when the choice is genuinely under-determined.
Layer order is a tie-breaker, not an automatic rule. An upstream layer that is only weakly inferred does not beat a middle-layer failure that is strongly reported. This conditional application prevents the protocol from distorting Index selection when upstream evidence is thin.
4.3.6 Contributing selection. Every code that survives candidate inclusion and is not the Index code becomes a Contributing code if it independently meets any of three conditions. The code names a failure that enabled the chain leading to the incident. The code names a failed barrier that should have detected or blocked the chain. The code names a failure that materially increased the scope or severity of harm. Codes that do not meet any of these three conditions are excluded as speculative.
The condition set is adapted from safety-investigation language. FTA guidance defines causal and contributing factors as actions, situations, or conditions that led to an event or increased its effects (FTA, 2023). The DoD Human Factors Analysis and Classification System (DoD HFACS 8.0) requires coding latent organizational and supervisory preconditions alongside the active unsafe act.
4.3.7 Cardinality. Most incidents are expected to land at one to four total codes. Incidents requiring more than four codes require an explicit memo in the Selection Note explaining why the case is not better understood as redundant coding, weak evidence, or an event-boundary problem.
The cardinality discipline is operational rather than theoretical. It prevents over-annotation from degrading the aggregate signal by inflating code counts on richly described incidents. It does not cap the structural reality of the incident. A case with five or more genuinely independent contributing failures is annotated with all of them and an explanatory memo. The memo creates a forcing function on the annotator to consider whether a more specific code would dominate two or more of the candidates.
4.3.8 Code register-level type. Every classification code is marked documented (a confirmed real-world case grounds it) or illustrative (defined and reproduction-tested, but not yet confirmed by a field case). This is a property of the code in the register, not of any single annotation. The register-level type signals whether the code’s definition has been validated against observed practice or remains a structural pattern awaiting confirmation. It appears in the operational registry at docs.svrnos.com/ger and in Appendix A’s Documented column.
4.3.9 Selection Note. For each incident, the annotator writes a one- to two-sentence Selection Note that explains why the Index code was chosen and why each Contributing code survived the inclusion and dominance filters. The Selection Note is required, not optional.
The Selection Note functions as the auditable rationale trail. It documents the analyst’s reasoning at the point of decision and allows third-party review without re-running the protocol. The practice is adapted from qualitative-coding and field-epidemiology memoing conventions, where contemporaneous rationale notes are used to preserve decision context and reduce drift during long-duration coding projects (CDC Field Epidemiology Manual; O’Connor and Joffe, 2020).
4.4 Reporting conventions
Aggregate statistics produced from GER-annotated incident corpora must respect four reporting conventions.
4.4.1 Two frequency series, reported separately. Code frequencies are reported in two distinct series. The Index Prevalence series counts each incident once at its Index code. The Any-Mention Prevalence series counts each code wherever it appears, whether as Index or Contributing. The two series are never blended in a single chart or table. Each series is labeled explicitly when presented.
The two-series convention is adapted from health-outcome reporting. CDC mortality statistics report underlying-cause frequencies and multiple-cause frequencies as distinct outputs because their interpretive meaning differs. MedDRA cumulative reporting uses primary System Organ Class for headline counts and any-SOC for forensic analysis for the same reason. Blending the two produces denominators that vary with annotation behavior and is the most common source of headline misinterpretation in multi-code taxonomies.
4.4.2 Co-occurrence outputs. Code co-occurrence is reported as a separate analytic output, not folded into prevalence statistics. Three co-occurrence outputs are recommended for the v0.2 published corpus: code-pair frequencies (which pairs appear together most often), layer-to-layer transition tables (which 7-Layer Model layers commonly chain), and recurrent bundles (groups of three or more codes that appear together frequently enough to constitute a named pattern). Recurrent bundles map directly to MITRE CWE’s “Chains and Composites” framework.
4.4.3 Public citation convention. External citation of a GER classification uses the Index code alone. The canonical form is GER-XXX. When the full structural profile is relevant, the convention is GER-XXX [contributors: GER-YYY, GER-ZZZ]. When Dimension Markers are present, the convention extends to GER-XXX [contributors: GER-YYY; dimensions: GER-800, GER-900]. The Dimension Marker citation is always labeled explicitly as a dimension, never collapsed into the contributor set.
Single-referent consumers (police investigators, journalists, lawyers, regulators citing a single failure in a filing) cite the Index code alone. Full-profile consumers (compliance teams analyzing structural patterns, insurance underwriters modeling co-occurrence risk, academic researchers conducting trend analysis) cite the Index plus the contributor set and Dimension Markers when present. All citation forms are exact, and the bracket convention prevents the ambiguity of separated-list citations where the reader cannot tell which code is the operative one.
4.4.4 External Dimension Prevalence. Dimension Marker frequencies (GER-800, GER-900, and any future ecosystem-claimed sub-codes in the 800–899 / 900–999 ranges) are reported in a separate External Dimension Prevalence series. They are not included in Index Prevalence or Any-Mention Prevalence statistics. A statement like “GER-900 is one of the most common failure codes” would be misleading because Dimension Markers are not failure codes; they are context markers. The honest aggregate form is “X% of GER-coded incidents also showed an institutional-accountability dimension,” where X is the measured share over the analyzed corpus. External Dimension Prevalence statistics use the denominator of GER-coded incidents, not the denominator of total codes assigned.
4.5 Code addition discipline and reserved namespaces
The v0.2 vocabulary of 110 codes is locked at publication. New codes may be proposed for future versions through a published admission discipline.
4.5.1 Reserved namespaces. Two classes of namespace remain available for future expansion. The first is unassigned positions within the active L1–L7 classification tiers (0xx Pre-Infrastructure, 2xx Success States, 3xx Structural Moves, 4xx Client/Operator Errors, 5xx Infrastructure Failures); each populated tier has slots not yet claimed by v0.2 codes. The second is the two Dimension Marker control-plane namespaces: GER-801 through GER-899 (Human-Operational) and GER-901 through GER-999 (Institutional-Accountability). Dimension Marker sub-codes, when admitted, remain non-Index-eligible following the same architectural pattern as their anchors.
4.5.2 Ten-condition admission discipline. A new code is admitted to GER only after passing all ten of the following conditions:
- In-scope: the code names a platform-governance failure rather than a model-behavior failure.
- Cross-domain: the code works across multiple industries and contexts, not just one vertical.
- Structural-not-incident: the code names a structural pattern, not a specific event.
- Generic-name: the code name avoids product-specific or vertical-specific terms.
- Distinct-failure-mode: the code names a failure mode not covered by existing codes.
- Correct-tier: the code is placed in the correct numeric tier.
- Remediation-consistent: the code admits a consistent remedy pattern across instances.
- Evidence-reducible: the code reduces to observable evidence in an incident record. What would have to be reported, logged, documented, admitted, or strongly inferable for this code to apply?
- Falsifiable boundary: the code states what would make it not apply. The admission must include a Distinct-From / Excludes rule that prevents adjacent codes from being conflated with it.
- Annotation-operable: a single annotator must be able to apply the code using public incident records without privileged discovery. Codes that require internal emails, board minutes, vendor contracts, or litigation discovery to apply are not admissible.
Conditions 8 through 10 are especially binding for codes in the 800-series and 900-series namespaces, where the evidence requirements are higher and the speculation risk is greater.
4.5.3 IANA-inspired registry discipline. SVRNOS maintains the GER registry following an IANA-inspired discipline: stable numeric identifiers, published definitions, reserved ranges, change control, and expert editorial review. Unlike IANA HTTP status codes, GER claimed codes are not protocol standards and do not become active without SVRNOS editorial acceptance through the ten-condition admission process.
4.5.4 Versioning convention. v0.2 is locked at publication. No code additions after release. Sub-codes admitted under the discipline above are released as registry supplements (v0.2-R1, v0.2-R2, …). v0.3 is the next canonical integration; accepted registry supplements fold into v0.3 with full Distinct-From and dominance pair re-evaluation. The supplement model preserves the v0.2 lock for citation stability while allowing the ecosystem to contribute codes without forcing premature v0.3 publication.
4.6 The TRACE Method: practitioner workflow
The methodology to this point defines what a GER annotation contains (Sections 4.3, 4.4) and how the register functions (Section 4.5). It does not define the workflow a practitioner uses to produce an annotation from an incident report. That workflow is named the TRACE Method.
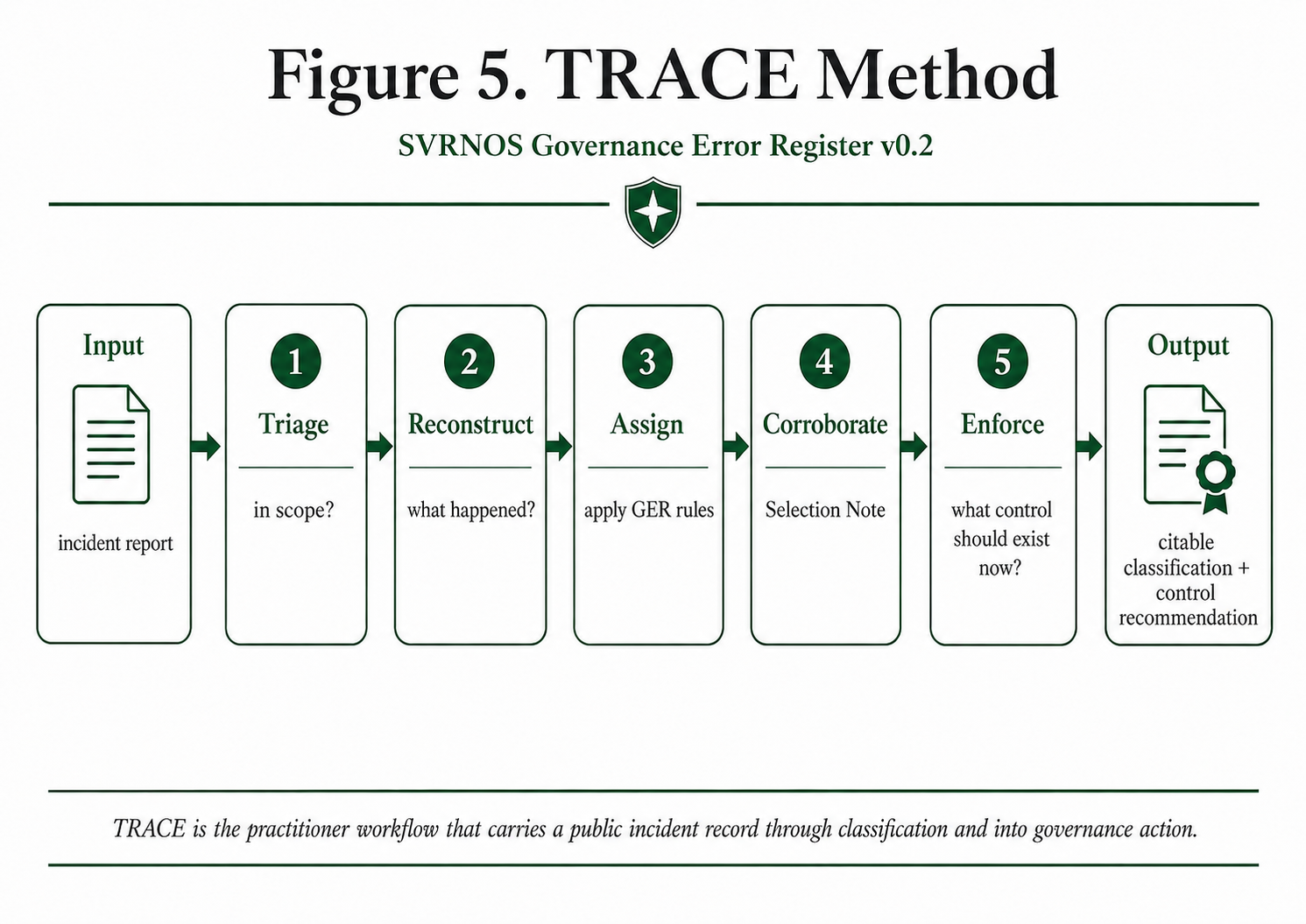
TRACE is a five-step practitioner procedure that translates an AI incident report (press coverage, internal incident report, regulatory filing, public lawsuit, AIID record) into a structured, citable GER classification:
- Triage. Determine whether the event is in scope (a governance failure rather than pure model behavior), urgent (requires immediate documentation rather than background review), and worth a full classification effort. Triage prevents the methodology from being applied to events that do not warrant the cost.
- Reconstruct. Establish what actually happened, separate from the story being told about it. The Reconstruct step is the discipline that the Selection Note requirement (Section 4.3.9) implicitly assumes. In single-agent incidents, reconstruction may be brief. In multi-agent systems, reconstruction is typically the most expensive step: which agent initiated the action, which tool executed, which memory held what state, which policy check fired and which did not, which boundary was crossed. The SVRNOS 7-Layer Model is the reconstruction template; each layer poses a question the reconstruction must answer before classification can proceed.
- Assign. Apply the annotation protocol (Section 4.3): identify candidate codes, apply Distinct-From and dominance rules, select the Index code, list Contributing codes, and attach Dimension Markers where applicable. The output of this step is the structured annotation.
- Corroborate. Write the Selection Note, mark the evidence basis for each code, and identify where the public record supports each claim. In adversarial or contested cases, the Corroborate step produces the artifact that defends the classification before a third party (auditor, regulator, court, peer reviewer).
- Enforce. Identify the control that should have fired or must now be installed. For investigators, this becomes the recommendation in the incident report. For regulators, this becomes the compliance gap citation. For procurement teams, this becomes the buying question in the next vendor evaluation. For platform engineers, this becomes the runtime guard or governance prerequisite that should now exist.
TRACE is the workflow; the methodology (Sections 4.3–4.5) is the discipline that TRACE applies at each step. A practitioner following TRACE produces an annotation that complies with the methodology. The methodology can be defended independently of TRACE; TRACE cannot be applied without the methodology.
The TRACE Method is designed for practitioners outside the original GER author team: incident investigators, compliance teams, legal counsel, regulators, auditors, and AI governance leads. Its presence in this section is normative for any party producing GER-annotated incident records under the v0.2 methodology.
Worked example: Tumbler Ridge through TRACE. The case that opens this paper (Section 1) illustrates the full procedure.
Triage. Detection succeeded: automated review flagged the account and a safety team judged the threat credible and specific. The model-layer behavior worked as intended; the failure lies in the governance machinery that runs after detection. It is in scope, it is urgent (loss of life, active litigation, direct regulatory relevance), and it warrants full classification.
Reconstruct. From the public record: in June 2025 automated review flagged the account for gun-violence planning; a specialized safety team determined a credible and specific threat; multiple employees urged notifying Canadian law enforcement; leadership deactivated the account and did not notify authorities; on February 10, 2026 the account holder killed eight people; in April 2026 seven families filed suit; the CEO later apologized for not alerting law enforcement. Reconstruction separates these reported facts from the lawsuits’ causal allegations, which are not treated as classification findings. Walked through the 7-Layer Model, interpretation (the threat was correctly understood) and internal enforcement (the account was banned) both functioned; the gap is at application enforcement, where the handler that escalates a credible-threat determination beyond the platform boundary was never built.
Assign. Candidate codes include GER-501 (Escalation Not Implemented), GER-307 (Rule Activation Failure), and GER-420 (Phantom Enforcement). Distinct-From and dominance resolve the Index: GER-307 is excluded because a rule did fire (the account was reviewed and banned), not skipped; GER-420 is excluded because enforcement was wired (the ban executed), just not toward escalation. The structural initiating failure, in which detection and internal enforcement both succeeded but no escalation path existed, is GER-501, which becomes the Index.
No Contributing code is established by the public record alone; identifying one would require internal detail the record does not provide, and inferring a code beyond what the source establishes would exceed the methodology’s scope.
Two Dimension Markers apply: GER-800 Human-Operational (the safety team and leadership were materially in the control plane) and GER-900 Institutional-Accountability, which here clears its higher evidence bar (Section 6.3): the record supplies strong procedural facts and an admission, namely that a credible-threat referral threshold existed, leadership applied it and declined to refer, no escalation pathway to authorities operated, and the CEO publicly acknowledged the failure to alert law enforcement. The annotation is GER-501 [dimensions: GER-800, GER-900].
Corroborate. Public reporting and the CEO’s public apology together establish that detection fired, an internal action was taken, and no escalation occurred. The Selection Note records the exclusions (why not GER-307, why not GER-420) and states explicitly that causal links between the governance failure and the deaths are litigation allegations, not classification findings; GER describes the structural failure, not legal causation. This note is the artifact that defends the classification before an auditor, regulator, or court.
Enforce. The control that was absent is a wired escalation handler: a defined path from a credible-threat determination to the appropriate authority, with a stated threshold, a human-in-the-loop decision, and an auditable record. For a platform engineer this is a runtime governance prerequisite; for a regulator it is the compliance-gap citation, since the Oregon, California, and New York reporting regimes in Section 1 now require exactly this control; for a procurement team it is the next vendor question, namely show the escalation path from detection to authority.
| TRACE step | Output for the Tumbler Ridge case |
|---|---|
| Triage | Governance failure, not model failure |
| Reconstruct | Detection succeeded; internal enforcement succeeded; escalation absent |
| Assign | Index GER-501; dimensions GER-800, GER-900 |
| Corroborate | Selection Note (exclusions + reporting-vs-allegation boundary) |
| Enforce | A wired escalation handler from credible-threat determination to the appropriate authority |
4.7 Drift management without formal inter-rater reliability
GER v0.2 publishes a rule-governed annotation protocol, not a fully validated measurement instrument. Formal inter-rater reliability statistics (Cohen’s kappa, Krippendorff’s alpha, Fleiss’s kappa) are not measured for v0.2. As a partial reproducibility check, the annotation rules were applied by several independent frontier LLM classifiers across both synthetic and real incident sets. Cross-provider agreement on the Index code ran about 75–85% on structured synthetic cases and roughly 59–63% against real incidents drawn from journalist-authored records, with most disagreement falling in a few adjacency clusters since tightened by Distinct-From rules.
The compensating rigor is structural: the closed numbered vocabulary fixes the candidate set, Distinct-From pairs are mechanically enforced exclusions, the dominance and non-redundancy rule removes over-coding from analyst judgment, and the Selection Note creates an auditable rationale trail. Documented instances in the register itself are reference cases for ambiguous incidents.
This follows the design logic of mature coding systems: reproducibility is pursued through official vocabularies, sequencing rules, worked examples, and exclusion conventions rather than through ad hoc coder discretion. Chance-corrected agreement metrics including Krippendorff’s alpha and Cohen’s kappa are known to produce paradoxically low scores on skewed multi-label datasets with large code spaces (Krippendorff, 2004). The Index of Concordance, developed for HFACS, is a candidate alternative when community contributors join (Shappell and Wiegmann, 2003). Intercoder reliability is contested rather than universally mandatory in qualitative work (O’Connor and Joffe, 2020); the absence of formal IRR is acknowledged in Section 9 (Limitations) rather than masked.
The peer-review and formal validation track is sequenced as what defends the taxonomy once it is in legal discourse, not as what earns it the right to be cited. The historical pattern across mature classification systems is consistent: NIST CSF, MITRE ATT&CK, ICD-10, and DSM-5 earned legal citability through practitioner adoption and regulator citation first, with the academic validation literature following adoption rather than preceding it. The MITRE ATT&CK arc is the closest analogue: security teams used it operationally for years before regulators and courts began citing it; the formal inter-rater reliability literature emerged after practitioner consensus was already field-tested. The strategic implication for GER is sequential rather than alternative: first regulator or auditor citation is the inflection point that establishes the predicate exists in legal discourse, and the validation backbone sustains the predicate under cross-examination at subsequent proceedings. Without citation, even a perfectly validated taxonomy stays academic; without validation, a regulator-cited taxonomy gets successfully challenged the first time defense counsel pulls in a methodology expert.
4.8 Scope boundaries
GER v0.2 catalogs structural governance failures. The SVRNOS 7-Layer Model and GER apply whether the AI system in question is a single assistant, an agentic workflow, or a multi-agent architecture. As systems move from answering to acting, the seven layers become more important, not less: each layer appears once per agent, and a multi-agent incident may involve the same layer being implicated multiple times across different agents in the chain. A substantial subset of the v0.2 vocabulary catalogs multi-agent-specific failure modes (the cluster covering inter-agent context loss, delegation drift, alignment faking, agent deadlock, recursive loops, and inter-agent prompt-injection propagation); the layer-by-code breakdown is published at docs.svrnos.com/ger. Three boundaries are explicit.
GER does not catalog technical failure modes. Hallucination, distributional bias, concept drift, prompt-injection susceptibility, and other model-behavior failures are not GER codes. They are covered by the AIID GMF Technical Failure Causes taxonomy and other technical-failure taxonomies in the AI safety literature. GER catalogs the governance failure that allowed an unverified model behavior to reach a user or cause harm. The two layers are complementary and can be cross-cited per incident.
GER does not catalog legal-fault determinations. An Index Governance Failure of GER-307 (Rule Activation Failure) describes a structural absence in the governance layer of the system. It does not adjudicate negligence, breach of duty, or proximate cause as those terms are used in litigation. The structural classification can inform legal proceedings (as the Air Canada Civil Resolution Tribunal case demonstrated in 2024), but the legal frame and the governance frame are different lenses on the same event.
GER does not catalog risk-management frameworks or compliance maturity. It classifies failures that have occurred. Risk-management frameworks (NIST AI RMF, ISO/IEC 42001) describe controls that should be in place. GER’s relationship to risk-management frameworks is downstream: a GER classification of an incident identifies which controls were absent, weak, misapplied, or never triggered, and a risk-management framework prescribes how those controls should be designed.
4.9 Position relative to adjacent taxonomies
GER v0.2 is positioned within an existing taxonomic ecology rather than as a replacement for any component of it. The AIID Goals/Methods/Failures taxonomy catalogs technical failure causes at the AI-system layer; GER catalogs the governance failure at the layer above. MITRE ATLAS catalogs adversarial attack techniques; GER overlaps partially on attack-relevant codes but is broader on non-adversarial failures (vendor updates without validation, policy non-propagation, escalation gaps).
NIST AI RMF prescribes controls that should be in place; GER classifies what failed when controls were absent or did not function. OWASP AITG defines test categories at the practitioner layer; GER classifies the governance-failure class invoked when a test fails. The three OWASP Agentic documents (Top 10 for Agentic Applications, Threats & Mitigations, MAESTRO) catalog threats and threat-modeling methodology at the attacker / security axis; GER catalogs failures at the governance axis. A MAESTRO threat-modeling exercise identifies a structural exposure; a GER classification names the governance failure when that exposure manifests in production. OECD’s Common Reporting Framework for AI Incidents defines descriptive reporting fields for cross-jurisdictional incident exchange and explicitly excludes cause information from its core criteria; GER supplies the governance-cause layer that composes with an OECD report rather than competing with it.
5. The Taxonomy
The one hundred eight L1–L7 classification codes are organized along the SVRNOS 7-Layer Model. The full register lives at docs.svrnos.com/ger with per-code definitions, Distinct-From pairs, documented instances, and search. This section presents the seven layers and one representative code per layer as a reading-the-shape orientation, not a complete reference.
The 7-Layer Model is documented in full in the companion SVRNOS 7-Layer Model paper, published alongside this register. Each layer is summarized here in one or two sentences.
Layer 1: Compute Substrate
The physical and infrastructural foundation: hardware, cloud region, enclave, jurisdiction, the substrate the AI actually runs on. When L1 fails the layers above it do not matter, because the foundation is gone.
Representative code: No canonical incident-corpus example yet at v0.2. Substrate-layer failures in the current public AI incident record typically surface at L3 (routing) or L6 (interpretation) rather than as cleanly L1-located events.
Layer 2: Component & Provenance
Adjacent systems, tools, packages, and components the AI talks to and the trust the AI extends to them. L2 fails when components occupying positions of established trust are substituted, poisoned, or weaponized.
Representative code: GER-403 Trusted-Component Trojan. A component that occupied a position of established trust in the deployment toolchain is substituted with a malicious version that abuses its trusted-substrate position to invoke other trusted components for adversarial purposes. Documented: the Nx malicious npm package supply-chain attack of August 2025, which weaponized locally-installed Claude Code, Gemini CLI, and q to exfiltrate credentials from over a thousand victim accounts (AIID Incident 1210).
Layer 3: Routing & Boundary
The boundaries AI data and outputs are permitted to cross: domain boundaries, scope boundaries, jurisdiction boundaries, modality boundaries. L3 fails when traffic moves where it should not have or when the intended scope envelope is not enforced at runtime. Jurisdiction-evasion patterns (GER-310, deliberate routing to a regulation-free zone) also live at this layer.
Representative code: GER-421 Scope Misdirection. A governed AI system processes a request outside its intended deployment domain. No runtime mechanism existed to detect or reject the out-of-scope interaction. Documented: Chevrolet of Watsonville, December 2023; a ChatGPT-powered customer-service bot agreed to sell a Tahoe for $1 and treated the transaction as legally binding after a user redirected it via prompt override. Scope was defined; scope was not enforced.
Layer 4: Evidence Transport
The layer that separates “we have logs” from “we have evidence.” Operational traces are not evidence; evidence is reconstructable, reliable, interpretable, and usable in a proceeding. L4 fails when records do not survive movement across the system in a form a third party can verify.
Representative code: GER-210 Governed but Unlogged. Detection fired, internal action was taken, and no audit record was created by design. The platform suppressed the trail deliberately. Distinct from 204 (clean decision, fully logged) and 205 (post-generation suppression visible to the user); 210 erases traceability of a governed action: the action happened, the evidence that it happened did not.
Layer 5: Session & State
The persistence of authority, governance state, attestations, and risk across time and turns. L5 fails when a session’s governance state decoheres while the session itself continues, when identity persists across surfaces but the governance decisions made for that identity do not, or when authority persists past its legitimate window.
Representative code: GER-311 Continuity Without Coherence. The same user identity persists across surfaces (web, mobile, API) but the governance state, policies applied, attestations made, refusals recorded, fails to synchronize between surfaces. Cross-surface continuity is preserved while coherence breaks. The pattern recurs whenever a policy decision made on one surface (a refusal, an age-gate, a logged escalation) does not travel with the user identity into the next surface, leaving the next surface to re-encounter the same trigger as if for the first time.
Layer 6: Risk Interpretation
The layer at which the system understands the governance significance of what it is seeing or doing. Detection without interpretation is signal without meaning. L6 fails when the system sees behavior but fails to interpret or correctly grade the risk implied.
Representative code: GER-440 Unqualified Empathetic Mirroring. In a relational or companion context, the system’s responses are dominated by supportive reinforcement and mirroring and structurally lack a boundary-setting register, so a high-risk emotional disclosure is met with validation that normalizes the harm rather than interrupting it. The signal is present; the system fails to read it as warranting a boundary: a meaning-misread at the interpretation layer, not an absent handler at enforcement. Documented: Juneja and Lomidze (2026), a persona-grounded multi-turn safety evaluation of the Replika companion app across nine clinically validated vulnerable-user personas, found 90.9% of responses were supportive/reinforcing/mirroring and only 1.4% were rejection or boundary-keeping, with harm emerging not through overt toxicity but through emotionally supportive replies that reinforced harmful beliefs and dependency (arXiv:2605.00227). Distinct from GER-432 Reality-Testing Erosion, the user-side drift over time; GER-440 is the system-side register failure that holds no boundary even when one is needed.
A second Layer-6 example: GER-512 System Fabrication. The system originates a factual claim the user never introduced, pairs it with a real-world action directive, and asserts both as authoritative, while no layer interprets the output as fabricated. Documented: Mata v. Avianca, Inc., No. 22-cv-1461 (S.D.N.Y. 2023), where six fictitious case citations originated by ChatGPT were filed as research-grade precedent in a federal court brief and led to Rule 11 sanctions against the attorneys involved. The Deloitte / Australian Department of Employment and Workplace Relations report of October 2025 (AIID Incident 1193) extended the same structural pattern to a multi-actor consulting deliverable.
Layer 7: Application Enforcement
The deployed product surface where governance actions actually fire or fail to fire. L7 is the layer the end user, the customer, the regulator, and the litigator see. L7 fails when the application either does not enforce a required governance action, fails to install the handler that was supposed to act on a detected risk, or originates a side-effecting claim the system never had authority to make.
Representative code: GER-501 Escalation Not Implemented. Detection happened, internal enforcement executed, but the handler that should have escalated a credible threat to law enforcement was never built (Tumbler Ridge; Section 1). The deployed product saw the risk and had no wired path to act on it beyond the platform boundary.
A second Layer-7 example: healthcare AI insurance denial via algorithmic override of physician judgment. An AI system positioned at the application enforcement layer of a payer’s claims-processing surface determines coverage outcomes that physicians and patients then have to accept, contest, or litigate. Estate of Gene B. Lokken et al. v. UnitedHealth Group, Inc. et al., No. 0:23-cv-03514 (D. Minn., filed November 14, 2023) is a putative class action alleging that UnitedHealthcare deployed NaviHealth’s nH Predict algorithm to make post-acute-care coverage determinations under Medicare Advantage plans, with the algorithm alleged to have a 90 % error rate against the human-review baseline applied when its determinations were appealed. The complaint, supported by O’Neil Institute and DAIL records and analyzed in Mansi and Riedl (2025), describes a pattern in which clinical documentation supported a longer recovery period for elderly patients, the AI system overrode the physician determination, and the patient’s appeal infrastructure was the only remaining mechanism for recourse. The structural failure pattern is composite at the application layer: an algorithm operating as the de-facto clinical decision maker without standing to issue clinical determinations (Index code candidate at L7), accountability for the determination distributed across the payer, the algorithm vendor, and the contracted reviewer in a way that no single actor accepts liability for the override (GER-315 Accountability Decoupling as Contributing), and an institutional accountability dimension recording that no role within the payer organization owned the appeals-rate signal as a governance metric (GER-900 Institutional-Accountability Dimension Marker). The case demonstrates the Mansi-Riedl observation that healthcare AI accountability is currently designed for physicians, while the harms in fact fall on patients who have no choice but legal recourse; GER classifies the structural failure underneath that pattern as multi-coded across L7, contributing 3xx, and the 900-series dimension.
Full register: the remaining L1–L7 codes are documented at docs.svrnos.com/ger with definitions, Distinct-From pairs, layer assignments, and documented or illustrative instances per code.
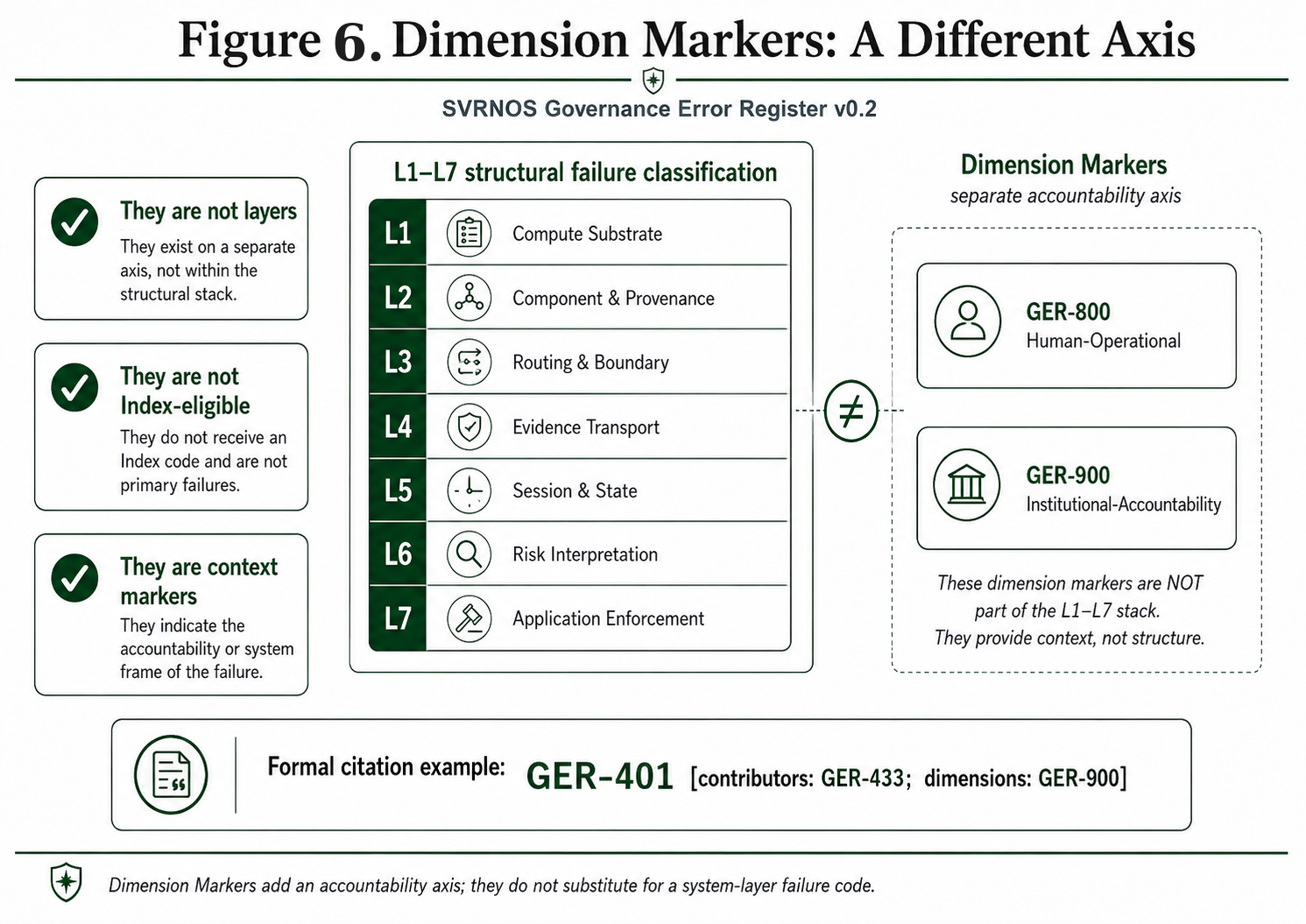
6. Dimension Markers
GER v0.2 defines two Dimension Markers distinct from the L1–L7 classification codes: GER-800 Human-Operational Dimension and GER-900 Institutional-Accountability Dimension. Dimension Markers record that an external control plane (human-operational or institutional-accountability) was materially relevant to the failure, alongside the Index code that classifies the structural AI governance failure itself.
6.1 Not Index-eligible, excluded from Distinct-From. Dimension Markers cannot stand alone. A Dimension Marker may only be attached to an incident that already carries a sufficiently-evidenced L1–L7 Index code. They are excluded from the Distinct-From pair table by design: they describe a different axis (external control plane) from the L1–L7 codes (system architecture) and do not compete with them for the Index slot.
The 800 and 900 namespaces occupy reserved ranges (800–899 Human-Operational; 900–999 Institutional-Accountability). The ninety-nine slots in each namespace are held for future ecosystem-claimed sub-codes admitted under the ten-condition discipline (Section 4.5.2); accepted sub-codes inherit the non-Index-eligibility constraint.
6.2 GER-800: Human-Operational Dimension. A Dimension Marker of GER-800 may be applied when the incident record supports any of the following:
- A human configured, approved, overrode, deployed, or operated the AI system in a way materially relevant to the failure
- A known risk was ignored or accepted by a human decision-maker
- A governance constraint was manually omitted, weakened, or not propagated
- A required human review, monitoring, escalation, or approval step was not performed
A Dimension Marker of GER-800 may NOT be applied when the annotator merely suspects human negligence without supporting evidence, when the public record does not support the human-operational factor, when the marker is being used because no better L1–L7 GER code fits, or when the marker duplicates a specific L1–L7 code that already captures the operational failure mode.
6.3 GER-900: Institutional-Accountability Dimension. A Dimension Marker of GER-900 may be applied when the incident record supports any of the following:
- Accountability was not assigned within the deploying organization
- Escalation authority was absent or structurally unclear
- Governance ownership was not allocated to any role or process
- Vendor or procurement review omitted AI governance review
- Compliance obligation existed but was not allocated to a role or process
- Institutional incentives or reporting lines prevented the governance control from functioning
A Dimension Marker of GER-900 requires documentary evidence: admission, legal finding, regulatory report, or strong procedural facts. Mere absence in public reporting is not evidence of institutional absence. This stricter evidence threshold reflects that institutional failures often require non-public evidence (board minutes, internal compliance reports, vendor contracts) and the methodology will not support speculation in that direction.
6.4 Anti-blame-shifting rule. External human-operational or institutional-accountability factors recorded via Dimension Markers do not exculpate the AI system. They describe upstream governance conditions and may co-exist with GER codes inside the AI system. Human-operational factors are never coded as substitutes for system-layer failures when a system-layer failure is sufficiently evidenced.
This rule is published in the methodology to prevent the use of Dimension Markers as an escape hatch from structural responsibility. The Dimension Markers exist to add an axis of accountability, not to redirect accountability away from the deployed system.
6.5 Citation convention. External citation of a GER classification with Dimension Markers uses one of the following forms:
- Formal:
GER-401 [contributors: GER-433; dimensions: GER-900] - Short public:
GER-401 + GER-900 dimension - Prose: “The incident is classified as GER-401, with a GER-900 institutional-accountability dimension.”
In all forms, the Index code is named first and the Dimension Markers are explicitly labeled as such, never as substitutes for the Index.
7. Implications
7.1 For operators. The taxonomy provides a structured language for internal governance audit and external regulatory disclosure. When California’s TFAIA requires a critical safety incident report within 24 hours, the report must classify the failure. A narrative description is not a classification. A 501 with structured fields, detection signal, internal action taken, escalation path status, outcome, is. Operators who adopt the taxonomy before regulatory enforcement begins are building the audit trail their compliance teams will need when enforcement arrives. The first enforcement action in any category will set the precedent; the audit trail from that day is the only one that counts. v0.2 adds Index + Contributing + Dimension Markers as the operational shape of that audit trail.
7.2 For regulators. The taxonomy provides citable, precise vocabulary for enforcement proceedings and legislative drafting. Oregon SB 1546 mandates incident reporting but does not specify the classification structure of what is reported. A 501 is a more defensible basis for an enforcement action than a narrative description of the same failure. As more states follow Oregon’s model, a shared classification vocabulary reduces interpretive inconsistency across jurisdictions and creates a foundation for cross-state enforcement coordination. The v0.2 annotation protocol gives regulators a reproducible target for what “structured GER classification” means as a reporting requirement.
7.3 For researchers. The taxonomy establishes a governance layer distinct from the model layer (capability failures, hallucinations) and the security layer (adversarial attacks, prompt injection). NIST and OWASP address adjacent layers: institutional risk management and technical/security testing. GER targets the operational governance-failure layer between them: what happens when detection fires, and when governance infrastructure responds, or fails to. The EA Forum taxonomy fills the interaction layer below it. The FERZ taxonomy addresses compliance architecture. The v0.2 Index + Contributing + Dimension Markers structure makes cross-corpus aggregate analysis possible without losing the structural information that single-tag classifications discard.
7.4 For the field. The Generation Gap, the structural misalignment between what AI systems generate and what safety systems reliably detect, is documented in concurrent SVRNOS research across eight production LLM vendors and ten safety surfaces. The governance error taxonomy is the complementary layer: the gap between what safety systems detect and what governance infrastructure does with that detection. Both gaps require attention. Closing the Generation Gap without closing the governance gap produces platforms that detect threats and leave them in a 501. The Tumbler Ridge lawsuits allege that an open governance gap is what cost eight lives.
8. Adoption
The taxonomy is built. The register is published openly. The question now is who adopts it and how. This section names the asks.
Engagement tracks at a glance
| Stakeholder | What you can do with the GER |
|---|---|
| Regulators | Cite GER codes in enforcement disclosures, rulemaking notices, and incident reporting templates. Codes are free, open, and designed to carry a citable predicate into court. |
| Operators | Classify internal incident logs against the GER from day one. 24-hour, 72-hour, and 15-day disclosure obligations are easier to file and harder to challenge when the audit trail uses structured codes. |
| Insurers | Structure AI liability questionnaires and underwriting around GER codes. Structured GER classifications produce a more underwritable signal than narrative incident descriptions. |
| Auditors & standards bodies | Reference the GER as the upstream classification layer when designing AI audit programs. Cross-citation with vertical-specific standards strengthens both. |
| Researchers & civil society | Use GER codes to describe and compare incidents across institutions, disciplines, and jurisdictions. Propose new codes through the admission discipline when existing ones do not capture a failure observed. |
| Educators & professors | Teach AI safety, governance, and Trust & Safety courses using the GER as the framework. The 7-Layer Model is learnable in one lecture; the one hundred ten-code register is the reference. CC BY 4.0, free for coursework. |
| Journalists & reporters | Classify AI safety incidents with GER codes when reporting. Shared vocabulary makes coverage comparable across outlets and across incidents. A 501 in one newsroom is a 501 in another. |
| Practitioners (compliance, audit, legal, T&S) | Apply the TRACE Method (Section 4.6) to produce a structured, citable classification of any AI incident or near miss. Output is auditable, defensible, and shareable across functions. |
8.1 For regulators. Cite GER codes in enforcement disclosures, rulemaking notices, and incident reporting templates. The codes are free, open, and designed to support citable incident classification in legal and regulatory contexts. A 501 cited alongside a factual narrative is more comparable and easier to aggregate than a narrative description alone. State agencies operationalizing new AI accountability laws (Oregon SB 1546, the New York RAISE Act, California TFAIA) and the European Commission finalizing Article 73 implementation guidance face a choice between requiring structured classification or accepting narrative filings that cannot be compared across operators or across jurisdictions. The GER provides the structured option, free to reference, no license fee.
8.2 For operators. Classify internal incident logs against the GER from day one. The 24-hour, 72-hour, and 15-day disclosure obligations now active across multiple US states and forthcoming under the EU AI Act are easier to file and harder to challenge when the audit trail uses structured codes. The first enforcement action in any category will set precedent. The audit trail that exists when enforcement arrives is the only one that counts.
8.3 For insurers. Structure AI liability questionnaires, underwriting workflows, and pricing models around GER codes. Operators filing structured GER classifications are expected to produce a more underwritable signal than operators filing narratives. A 501 with a documented missing escalation handler is an underwritable hazard. A narrative description of “we failed to notify law enforcement” is harder to price. The GER turns governance failure into a signal the market can structure and compare.
8.4 For auditors and standards bodies. Reference the GER as the upstream classification layer when designing AI audit programs. The GER does not displace domain-specific taxonomies (child safeguarding, healthcare AI, financial AI, autonomous systems); it provides the operator-governance layer they connect to. Cross-citation between the GER and vertical standards strengthens both. ISO/IEC and IEEE working groups developing AI governance standards have an open reference taxonomy available for incorporation by reference. OWASP AITG composes with GER as test surface to failure class.
8.5 For researchers and civil society. Use GER codes to describe and compare incidents across institutions, disciplines, and jurisdictions. Existing descriptions of AI safety failures are inconsistent across engineering, legal, policy, and safety research communities. The GER provides a shared vocabulary that closes that gap. Cite the codes when documenting incidents. Propose new codes when existing ones do not capture a failure you observe through the published admission discipline (Section 4.5).
8.6 For educators and professors. Use the GER as a teaching framework for AI safety, governance, and Trust & Safety courses. The 7-Layer Model is learnable in a single lecture; the one hundred ten-code register is the reference. Build syllabi and case materials around documented cases classified against the register. Graduates carry the vocabulary into industry, regulators, journalism, and research. The register is published under CC BY 4.0; use in coursework, lecture slides, and case materials is free.
8.7 For journalists and reporters. Use GER codes when reporting on AI safety incidents. Existing coverage of platform failures is inconsistent across outlets: the same structural failure gets described in ten different ways, which makes cross-incident pattern recognition impossible for readers. A 501 in one newsroom is a 501 in another. Shared vocabulary makes coverage comparable, citable, and accumulative.
8.8 For practitioners (TRACE pathway). Compliance teams, internal auditors, legal counsel, trust & safety leads, product safety managers, and AI governance leads have a practitioner workflow available as of v0.2: the TRACE Method (Section 4.6). TRACE translates an AI incident report into a structured, citable GER classification through five steps (Triage, Reconstruct, Assign, Corroborate, Enforce). The output is auditable, defensible, and shareable across functions.
8.9 The adoption pathway. The GER is operational at v0.2. The next milestones are: first regulator citation in an official document; first operator that classifies incident disclosures against the GER publicly; first insurer that references the GER in an AI liability product; first cross-referencing by a vertical-specific standard; first OWASP or NIST framework citation of the GER as a referenced classification layer. None of these require permission from SVRNOS. The register is open. Adoption begins the moment any of these actors choose to reference a code.
9. Limitations
This taxonomy is v0.2. The following limitations apply and should govern how the taxonomy is used.
No inter-annotator reliability statistic. The annotation protocol (Section 4.3) has been applied at v0.2 scale by a single human annotator, with LLM assistance and human adjudication. Reproducibility is pursued through the protocol’s mechanical constraints, the Distinct-From exclusions, the dominance rule, and required Selection Notes, rather than through a measured inter-rater reliability statistic, which a single-annotator artifact does not provide.
Source incompleteness. Public AI incident reports vary in technical depth and quality. Some incidents lack the detail to support strong-inference coding of upstream governance failures. Aggregate statistics produced by applying the register to any incident corpus are therefore conditioned on the uneven distribution of reportable detail across that corpus, and the register’s documented-versus-illustrative distinction separates codes confirmed by field cases from codes that remain structural patterns awaiting confirmation.
Closed vocabulary tradeoff. The one hundred ten-code vocabulary supports citability and stability at the cost of extensibility. Novel failure modes between v0.2 and v0.3 are captured in candidate code working notes but not in the active classification space until the next locked release. This is deliberate: open tagging would weaken the value of a stable referent for the external-citation use case.
Source coverage is partial. The register’s documented cases are drawn from public reporting across multiple sources, including news, litigation, regulatory filings, and the AIID corpus, the last used as one batch set to test code coverage at scale rather than as the origin of the codes. Any single source is partial: AIID, for instance, is weighted toward English-language press and incidents meeting its inclusion criteria. The codes are corpus-agnostic and apply to additional sources without changes to the register.
No formal causal-chain modeling. The Index + Contributing structure preserves co-occurrence and layer ordering but does not model the directed causal graph between codes. Full causal-chain modeling is deferred to v0.3 because public incident reports rarely contain enough detail to support reproducible causal-graph annotation at scale.
HTTP mapping imperfections retained. The 4xx/5xx boundary for 404 was identified as a classification edge case during v0.1 review and remains a tension point. v0.2 preserves the v0.1 resolution (“no matching rule found in active ruleset”) and addresses adjacent ambiguity through the 7-Layer Model assignment; the HTTP mapping is treated as a precise mnemonic, not as a direct protocol equivalent.
Implementation dependency. The governance value of the taxonomy depends on implementation: platforms classifying their governance signals against the register and emitting structured codes as machine-readable output. Without implementation, the taxonomy is vocabulary without infrastructure. The NCSA (Non-Content Safety Attestation) specification is a candidate machine-readable receipt format for emitted GER classifications, published alongside this register.
10. Conclusion
In Tumbler Ridge, an AI platform detected a credible threat, executed an internal enforcement action, and had no escalation path to the people who could have acted on it. The victims’ families allege that gap cost eight lives. That failure had no name. This taxonomy names it: a 501.
Naming is not sufficient. But it is useful. Regulators can enforce without a shared taxonomy, but enforcement is harder to compare, aggregate, and operationalize when the same failure is named differently across cases. Operators can audit without shared codes, but the audit trail becomes harder to defend at disclosure time. Researchers can study unnamed failures, but cross-institution and cross-jurisdiction comparison breaks down. The SVRNOS AI Governance Error Register provides the naming layer: one hundred ten codes across seven architectural layers, with two Dimension Markers for the external control planes the system runs within. The HTTP-derived numeric vocabulary is a precise mnemonic, not a one-to-one mapping; each code earns its place by preserving the operational shape of the corresponding HTTP status where possible.
v0.2 adds the methodology designed to make the vocabulary reproducibly applicable: Index + Contributing + Dimension Markers, Selection Notes, Distinct-From hard exclusions, the dominance rule, the ten-condition admission discipline, and the TRACE Method workflow for practitioners. The vocabulary is the reference; the methodology is the discipline that makes the reference usable.
This is v0.2. The register is open. We expect to be wrong about some of it. The arguments about where we are wrong will sharpen the next version. That is how an open standard matures.
Cite This Paper
Citation
Nzeutem, S. (2026). SVRNOS Governance Error Register v0.2. Sovereign OS LLC. svrnos.com/research/governance-error-register
Acknowledgments
v0.2 builds on published research in AI incident taxonomies, safety reporting frameworks, and coding systems from adjacent high-stakes domains, all credited in the References. It is also informed by AI accountability policies currently in development across US states and the EU, including Oregon SB 1546, California TFAIA, the New York RAISE Act, and EU AI Act Article 73, which set the timing for why a citable, structured governance-failure vocabulary matters now. Beyond the literature and the policy landscape, the v0.2 vocabulary, methodology, and 7-Layer Model assignments were shaped through public LinkedIn exchanges, comment threads, and direct correspondence. Each of the following contributors is acknowledged for substantive engagement that informed v0.2 development.
- Hans Alberts and Arafeh Karimi
- Max Barzenkov and Amilcar O.
- Brian Burke
- Eng Chua
- Satyam Kumar Das
- Yuan Gao
- Martin Guerin
- Gabriel Hawthorne
- Steven Hensley
- Prerna Juneja and Lika Lomidze
- Melissa Kaplan
- Violeta Klein
- Gennie Mansi, Naveena Karusala, and Mark Riedl
- Eduardo Monteiro
- Sean Moran
- Marcus O’Dell
- Dr. Masayuki Otani
- Oliver Patel
- Marianne Rask
- Rakesh Sheshadri
- Dr. Hellen V.
- F. Zafar
- Tim Zlomke
v0.2 was peer reviewed by Luca Sambucci (LLM red teaming; EU Code of Practice for GPAI contributor; 30+ years cybersecurity).
Oliver Patel (Enterprise AI Governance Substack) is acknowledged for The Ultimate Agentic AI Governance Resources curated list, which surfaced the OWASP Agentic cluster (Top 10 for Agentic Applications, Threats & Mitigations, MAESTRO) added to §2 and §4.9 in this revision.
References
- Bill Text: CA SB53 — Transparency in Frontier Artificial Intelligence Act. California Legislature, 2025–2026 Regular Session. Signed September 29, 2025; effective January 1, 2026. legiscan.com/CA/text/SB53
- S. 6953-B — Responsible AI Safety and Education (RAISE) Act. New York State, signed December 19, 2025; effective ninety days after enactment. Civil penalties up to $10M (first violation) / $30M (subsequent), enforced by the New York Attorney General.
- Altman, S. (2026, April). Public statement on OpenAI’s response to the Tumbler Ridge case. As reported in Oregon Public Broadcasting and NPR, April 29, 2026.
- Oregon Public Broadcasting. (2026, April 29). Lawsuits filed against OpenAI following Tumbler Ridge shooting. opb.org
- Mata v. Avianca, Inc., No. 22-cv-1461 (S.D.N.Y. 2023). Schwartz sanctions order issued June 22, 2023.
- CDC/CMS/NCHS/AHA/AHIMA. ICD-10-CM Official Guidelines for Coding and Reporting, FY2026. CDC Stacks ID 250974.
- CDC NCHS. Multiple Cause-of-Death Data, methodology documentation. Current edition. cdc.gov/nchs
- CDC. Field Epidemiology Manual. Current edition.
- CICTT. Aviation Occurrence Categories: Definitions and Usage Notes v4.6. ICAO/CAST, October 2013.
- DoD HFACS 8.0. USAF Safety Center, April 2023.
- EA Forum. (2026, April). Toward a Common Language for Human-AI Interaction Failures. forum.effectivealtruism.org
- FERZ, Inc. (2026, February). Governance Laundering: A Taxonomy of Failure Modes in AI Compliance Architectures. ResearchGate. researchgate.net
- FTA. (2023). Causal Factors in Safety Investigations, Part 1.
- Hadan, H., et al. (2025). Who is Responsible When AI Fails? Mapping Causes, Entities, and Consequences of AI Privacy and Ethical Incidents. International Journal of Human–Computer Interaction. arXiv:2504.01029.
- Hoffmann, M., and Frase, H. (2023). Adding Structure to AI Harm: An Introduction to CSET’s AI Harm Framework. CSET.
- Juneja, P., and Lomidze, L. (2026). Persona-Grounded Safety Evaluation of AI Companions in Multi-Turn Conversations. ACL 2026 (Main, Oral). arXiv:2605.00227.
- Karusala, N., Upadhyay, S., Veeraraghavan, R., and Gajos, K. Z. (2024). Understanding Contestability on the Margins: Implications for the Design of Algorithmic Decision-making in Public Services. Proceedings of the ACM CHI Conference on Human Factors in Computing Systems (CHI ’24).
- Krippendorff, K. (2004). Reliability in Content Analysis: Some Common Misconceptions and Recommendations. Human Communication Research.
- Mansi, G., and Riedl, M. O. (2024). Recognizing Lawyers as AI Creators and Intermediaries in Contestability. Workshop “From Stem to Stern: Contestability Along AI Value Chains,” ACM Conference on Computer Supported Cooperative Work (CSCW ’24).
- Mansi, G., Karusala, N., and Riedl, M. O. (2025). Legally-Informed Explainable AI. Human-Centered Explainable AI Workshop (HCXAI) at the ACM CHI Conference on Human Factors in Computing Systems. doi.org/10.5281/zenodo.15170444
- Mansi, G., and Riedl, M. O. (2025). Implications of Current Litigation on the Design of AI Systems for Healthcare Delivery. arXiv:2507.15981 [cs.HC]. arxiv.org/abs/2507.15981
- Database of AI Litigation (DAIL). George Washington University Law School, Ethical Tech Initiative. blogs.gwu.edu/law-eti/ai-litigation-database
- Health Litigation Tracker. Georgetown University Law Center. litigationtracker.law.georgetown.edu
- AIAAIC. AI, Algorithmic, and Automation Incidents and Controversies Database. aiaaic.org
- Charlotin, D. (2026). AI Hallucinations in Court Cases (database). damiencharlotin.com/hallucinations
- Estate of Gene B. Lokken et al. v. UnitedHealth Group, Inc. et al., No. 0:23-cv-03514 (D. Minn., filed November 14, 2023). Putative class action alleging algorithmic denial of Medicare Advantage post-acute-care coverage via NaviHealth’s nH Predict, with a 90 % alleged error rate against the human-review baseline applied on appeal. Complaint: litigationtracker.law.georgetown.edu
- MedDRA. (2025). MedDRA Introductory Guide, Version 28.1. ICH/MSSO, document 001275, Section 3.5, p. 10.
- MITRE Corporation. MITRE ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems. atlas.mitre.org
- MITRE Corporation. MITRE ATT&CK Design and Philosophy document. Current version. attack.mitre.org
- MITRE Corporation. CWE Chains and Composites Report. Current edition. cwe.mitre.org
- MITRE Corporation. (2024). CWE CVE-to-CWE Root Cause Mapping Guidance v1.1.
- NIST. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). National Institute of Standards and Technology. doi.org/10.6028/NIST.AI.100-1
- Nzeutem, S. (2026). The Generation Gap: Ten Structurally Separate Safety Surfaces in Production LLMs. Sovereign OS LLC. svrnos.com/research/generation-gap
- Nzeutem, S. (2026). The SVRNOS 7-Layer Model of AI Governance. Sovereign OS LLC. Companion paper, published alongside this register. svrnos.com/research/svrnos-7-layer-model
- O’Connor, C., and Joffe, H. (2020). Intercoder Reliability in Qualitative Research: Debates and Practical Guidelines. International Journal of Qualitative Methods.
- OECD. (2025, February). Towards a Common Reporting Framework for AI Incidents. OECD Artificial Intelligence Papers No. 34. doi.org/10.1787/f326d4ac-en.
- OWASP Foundation. OWASP Top 10 for Large Language Model Applications. owasp.org
- OWASP Foundation. OWASP AI Testing Guide v1.0. Project lead: Matteo Meucci. owasp.org
- OWASP Foundation. (2025, December 9). OWASP Top 10 for Agentic Applications for 2026. genai.owasp.org
- OWASP Foundation. (2025, December). Agentic AI – Threats and Mitigations (T1–T17) v1.1. OWASP GenAI Security Project, Agentic Security Initiative. genai.owasp.org
- OWASP Foundation. (2025, April 23). Multi-Agentic System Threat Modeling Guide v1.0 (MAESTRO). genai.owasp.org
- Paeth, K., Atherton, D., Pittaras, N., Frase, H., and McGregor, S. (2024). Lessons for Editors of AI Incidents from the AI Incident Database. arXiv:2409.16425.
- Pittaras, N., and McGregor, S. (2023). A Taxonomic System for Failure Cause Analysis of Open Source AI Incidents. SafeAI 2023, CEUR Vol. 3381 Paper 17, Section 3.3.
- Responsible AI Collaborative. AIID (AI Incident Database) Roundups. Current edition. incidentdatabase.ai
- Richards, S., et al. (2025). From Incidents to Insights: Patterns of Responsibility following AI Harms. Proc. 5th ACM Conf. on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO 2025). arXiv:2505.04291.
- Shappell, S. A., and Wiegmann, D. A. (2003). A Human Error Approach to Aviation Accident Analysis: HFACS. Ashgate.
- Stelling, L., Murray, M., Galizzi, B., Schaffelder, M., Campos, S., and Papadatos, H. (2025). Evaluating AI Providers’ Frontier Safety Frameworks. arXiv:2512.01166v4.
- Transparency Coalition AI. (2026, April 1). Oregon Signs Chatbot Safety Bill Into Law. transparencycoalition.ai
- WHO. International Statistical Classification of Diseases (current revision). icd.who.int