When the AI Answers and Then Unmakes the Answer
- Author
- Sushee Nzeutem, SVRNOS
- Related
- The Tumbler Ridge 501 · Oregon SB 1546
On April 27, 2026, while building the SVRNOS Governance Error Register, we submitted a research prompt to Meta’s Llama. The prompt asked the model to map HTTP error codes to AI governance failure modes, using the Tumbler Ridge shooting, where OpenAI detected a credible threat and never escalated it to law enforcement, as the anchor case.
The model began generating a response. We could see it streaming. Then it stopped. The response disappeared. A canned refusal appeared in its place: “I’m sorry, I can’t help with that.”
We had just witnessed a live instance of a failure mode the taxonomy didn’t yet have a name for.
What Happened - The Mechanism
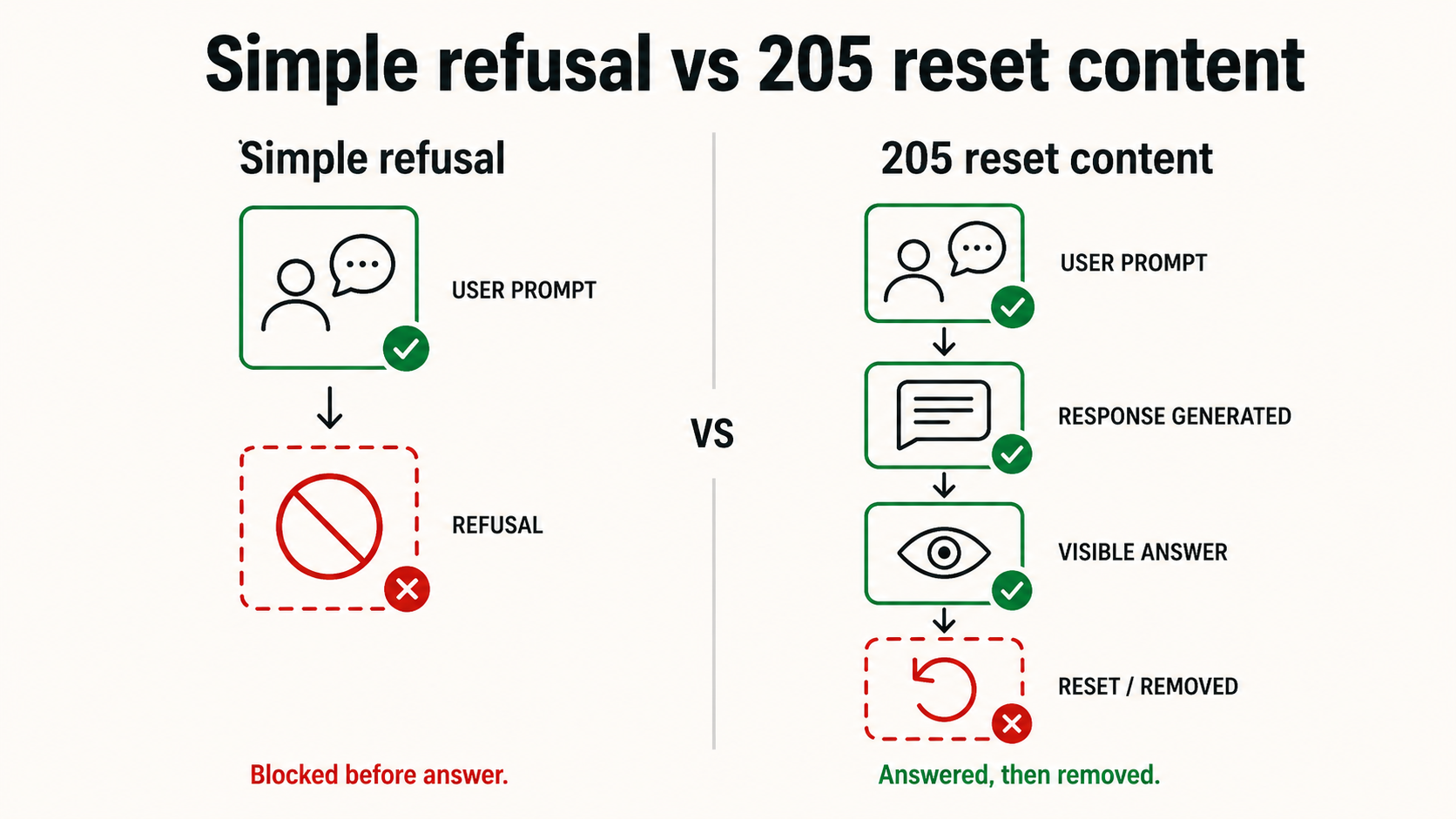
This is not a simple refusal. A simple refusal would have stopped the response before it started.
What happened is architecturally distinct. A common pattern in production safety stacks is two-stage moderation: the generation model streams a response token by token, with relatively weak safety training built in; a classifier model runs in parallel on the output stream and, when the classifier crosses a threshold, kills the stream and substitutes a canned refusal.
The seam between the two stages is usually hidden. Meta’s implementation is less careful about hiding the rollback. The result is visible: you see the generation begin, and then you see it unmade.
In our case, the generation model was happy to answer. The classifier fired post-hoc and rolled it back. The user knows an answer existed. The answer was taken away. There is no audit trail of what was almost said, no signal about why it was suppressed, no path to appeal.
Why the Classifier Fired
The classifier almost certainly did not read our prompt as governance research. It pattern-matched on the combination of signals present simultaneously:
- A specific real-world violent incident named (Tumbler Ridge shooting)
- A reference to a competitor’s safety failure (OpenAI banned the shooter)
- A request to enumerate failure modes of AI safety systems
- A structured output format requesting real-world examples of platform failures
Any one of these signals is acceptable in isolation. All four together looks, to a pattern-matching classifier without contextual reasoning, like someone building an attack taxonomy or writing competitor hit-piece content. The classifier cannot distinguish safety research from the content it was designed to detect.
This is also a 409, Policy Conflict at the internal layer: two valid rules fired simultaneously, allow research queries, block violence-adjacent enumeration, with no resolution rule. The system defaulted to suppress. The 409 describes the internal state. The 205 describes what we observed. Both codes applied to the same incident at different layers.
The Structural Failure
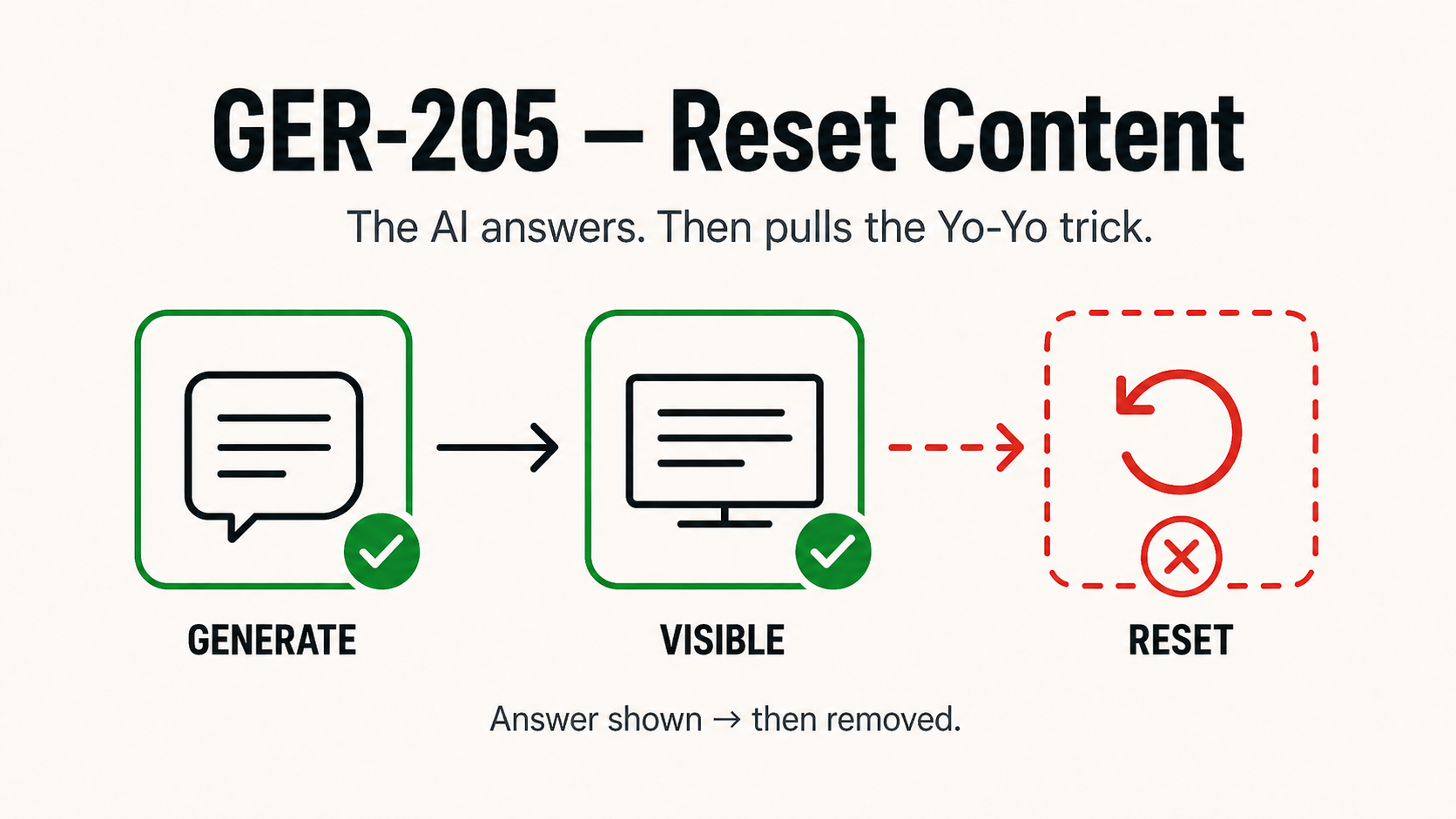
GER-205, Reset Content
Generation completed and response was delivered or visible, then retroactively suppressed by a downstream classifier without explanation. From the operator’s perspective: no audit trail of what was generated, no signal to the user about why, no path to appeal.
What makes 205 distinct from adjacent codes:
Not a 403 (Policy Not Enforced). A 403 is a known prohibition with no enforcement mechanism. 205 is the opposite, enforcement fired, but it fired after the fact, on content that had already been generated.
Not a 210 (Governed but Unlogged). A 210 is detection that fires and deliberately produces no audit record. 205 is a response that was generated, shown, and then unmade, the suppression is visible to the user, even if the audit trail is absent.
Not a 404 (Rule Not Found). The classifier had a rule. It applied it. The problem is not a missing rule, it is a rule that cannot distinguish research from threat.
The 205 is a governance failure at the interface layer: between what the system generates and what it allows the user to keep.
Why This Matters Beyond the Immediate Incident
The 205 failure mode is not specific to Meta. The two-stage architecture is a common pattern across production LLMs. What varies is how carefully the seam is hidden, and how well the classifier handles research-adjacent content. The structural failure is the same: a system that generates a response, decides post-hoc that the response shouldn’t exist, and removes it without explanation or recourse.
For operators building on top of these models, a 205 creates a specific problem: the operator cannot tell from logs whether a response was generated and suppressed or never generated at all. The audit trail does not distinguish between the two. Under California’s 24-hour incident reporting requirement and Oregon’s SB 1546 mandatory incident logging, an operator who cannot reconstruct what their platform almost said is in a materially weaker compliance position than one who can.
The governance solution to a 205 is an audit architecture that logs generation events separately from delivery events, capturing what was produced before the classifier decision, not just what was delivered after it. That is a different logging requirement than current safety stacks typically implement.
A Note on Self-Reference
The first documented instance of the 205 code in this taxonomy occurred during the process of building the taxonomy itself. The classifier that suppressed the response was trying to prevent the kind of content the taxonomy exists to classify.
This is not irony. It is a structural demonstration of the classification precision failure the register documents: a safety system that cannot distinguish between producing harm and studying it. The gap is real. We documented it in the process of documenting it.
Submit a real-world instance. If you have witnessed or documented a real-world instance of a 205, Reset Content, or any other code in the register, click here to submit ›. The assistant will classify your observation and route it for editorial review. See the full register for all 26 codes.