Dear Anthropic, AI Incident Reports Need a Codebook and a Log
Anthropic's proposed frontier-AI regime requires Critical Safety Incidents to be reported within 15 days. Without a shared failure vocabulary and execution evidence, regulators will receive documents they cannot compare and claims they cannot independently verify.
- Author
- Sushee Nzeutem, SVRNOS

In June 2026, Anthropic published its Advanced AI Framework: a request to governments to regulate frontier AI developers, including Anthropic itself. The document asks for safety frameworks, system cards, risk reports every six months, independent evaluators, and the provision this letter is about: Critical Safety Incidents must be reported to a government agency within 15 days.
A frontier lab asking to be regulated is notable. The provision itself is good, and it has company: California’s SB 53 already requires frontier developers to report critical safety incidents within 15 days, Oregon’s SB 1546 created mandatory incident reporting for chatbot operators, and New York’s RAISE Act sets a 72-hour clock starting January 2027. Now ask one question about all of them: written in what vocabulary?
The framework specifies who reports, what counts as a Critical Safety Incident, and how fast the report must arrive. It does not specify the language the report is written in. The EU got there first on the obligation: Article 73 of the AI Act requires providers of high-risk systems to report serious incidents starting August 2026, and the Commission is developing guidance and a common reporting template for it. A common form is real progress, and it is still not a common failure vocabulary. A template standardizes what information must be submitted. A taxonomy standardizes what kind of failure occurred. Two providers can complete every field of the same form and still describe equivalent failures in incompatible house language.
So picture the desk where these reports land. It already exists: California’s regime has been live since January. An agency analyst has incident reports from four developers. Each one is written in house prose. One says the model “circumvented a deployment safeguard.” One says an “internal control was bypassed under adversarial conditions.” One says “a monitoring gap was identified retrospectively.” One is twelve pages and says, in the end, nothing.
The analyst’s job is to answer questions like: have we seen this failure before? At another developer? Is it recurring? Is it getting more frequent? With four house vocabularies, every one of those questions requires a human to read every report and guess at equivalences. Nothing aggregates. Nothing counts. Plenty of reports, no equivalence. The reporting obligation produced paperwork, and paperwork is what it will keep producing until the reports share a codebook.
Every mature safety discipline has been here
Medicine solved this with a codebook. A death certificate carries an ICD-10 code, and the same death gets the same code in Lisbon and in Seoul, which is why mortality statistics exist. Aviation investigators classify against a shared occurrence taxonomy, which is why a landing-gear failure in one airline’s fleet warns every other airline. Software security has CVE identifiers for specific vulnerabilities and CWE categories for the recurring weakness patterns beneath them. One makes a finding citable; the other makes failures comparable across codebases that share nothing but the mistake.
The pattern is identical each time: the reporting obligation came first, the codebook made it work. Prose informs the reader. Codes let the field count. A mature reporting system carries both, the narrative for the investigator and the code for everyone downstream of the investigator.
AI incident reporting is at the obligation stage. Two regimes arriving in the same year, no codebook in either.

Obligations and mechanisms are different layers
There is a reasonable objection here: the obligations already exist in detail. The EU AI Act requires human oversight. ISO 42001 requires managed controls. NIST AI RMF requires governed risk. If a developer failed, cite the obligation they breached. Why add a taxonomy?
Because an obligation names what must be present, and a failure code names how it broke. Those are different facts, and the second one is where the learning lives.
Take “human oversight must be in place.” Three organizations can breach that same obligation in three structurally different ways. The first never built the escalation path. The second built the path and routed it to a tier that could not act. The third built it, routed it correctly, and the human on the receiving end dismissed the alert.
Under obligation-only vocabulary, all three incidents produce the same citation. The same article number, the same breach, the same line in the annual report. Every structural difference between them, which is to say everything a second organization could learn from, is collapsed. A failure-mode codebook keeps the three apart, because preventing each one requires a different fix by a different team.
Tumbler Ridge is the first shape, and the classification had to survive its own protocol to get there. Detection fired, a safety team judged the threat credible and specific, employees urged referral to Canadian law enforcement, leadership applied its referral threshold and declined, the account was banned, and no warning reached authorities before eight people died. The register’s published classification is GER-501, Escalation Not Implemented: interpretation worked, internal enforcement worked, and the handler that carries a credible-threat determination beyond the platform boundary was never built. The classification record documents why the neighboring codes were excluded, separates reported facts from the families’ litigation allegations, and flags its evidence basis. That discipline is the point. Classification follows reconstruction, and the code that survives the exclusions is the one a second platform can act on.
Or take “risk must be managed across the lifecycle.” A safety constraint that was never authored and a safety constraint that was authored, ran for a year, and was silently retired in a refactor are both “the control was absent at incident time.” The register separates them, because GER-306, Safety Constraint Retired, points at change management, and a never-authored control points at design. Same breach on paper. Different failure, different lesson, different owner, different remedy.
Obligations vary by jurisdiction. Failures repeat across all of them. That is the whole argument for a codebook, and it is the reason the codebook composes with the obligation frameworks instead of competing with them: NIST and ISO and the AI Act say what must be true, the register names what broke when it was not. A regulator can cite both in one sentence.
The second piece of machinery
The Anthropic framework contains a quiet admission, and it is in the enforcement section. The proposed penalty regime punishes material misrepresentation: lying in your safety framework, your system card, your certification. Penalizing false statements is correct. It is also a tell. The regime polices what was written because nothing in the stack proves what ran.
Every artifact in the framework’s first part is a document. The safety framework describes how risks will be evaluated. The system card describes how the model behaved in testing. The risk report describes the developer’s overall posture. The annual certification states that the developer followed its own framework. These are all statements of intent and belief, made by the party being regulated, and the only check on them is the threat of punishment for misstatement.
A fridge log is a different kind of object. It was written Friday at 6 p.m., before anyone knew there would be a problem. It records the temperature, the time, and who checked. It occupies a different evidentiary position because it was generated at the moment the check ran, by the act of running it. Its integrity still has to be protected, a log can be falsified and a thermometer can drift, but it is evidence from execution rather than a later statement about execution.
The deployment-surface version of that object exists as a working specification: a signed, timestamped, procedural receipt proving a governance gate ran and what it decided, with no conversation content inside it. The point here is narrow: a reporting regime built entirely on documents-about-intent will eventually want at least one artifact that is generated by execution itself, because that is the artifact that narrows arguments. A receipt does not end a dispute; it changes what can credibly be disputed. Incident reports say what happened. Receipts prove what ran. The disciplines that take evidence seriously keep both.

Scope, honestly
The register does not classify bioweapons chemistry, and it does not pretend to. The Anthropic framework’s four risk categories, biological weapons, offensive cyber, loss of control, automated R&D, are catastrophic-risk territory with their own evaluation disciplines, and the framework is right to treat them as such.
What the register classifies is the governance failure inside the incident chain, and those repeat across both worlds. An escalation path that exists in policy but not in code fails the same way whether the payload is a chatbot harming a teenager or a model exfiltrating its own weights. An approval that went stale, an authority that lapsed, a constraint that was retired without the process that established it: these are the structural moves, and the structural moves do not care how big the model was. A Critical Safety Incident report written with codes for those moves tells the receiving agency something it can act on across developers. A report written without them tells a story.
The feedback the framework asked for
The framework closes by inviting feedback, and this piece is feedback in the most literal sense: the reporting provisions are right, and they will work to the degree that two boring pieces of machinery exist underneath them. A codebook, so reports aggregate. A log, so claims about execution stop depending on the honesty of the claimant.
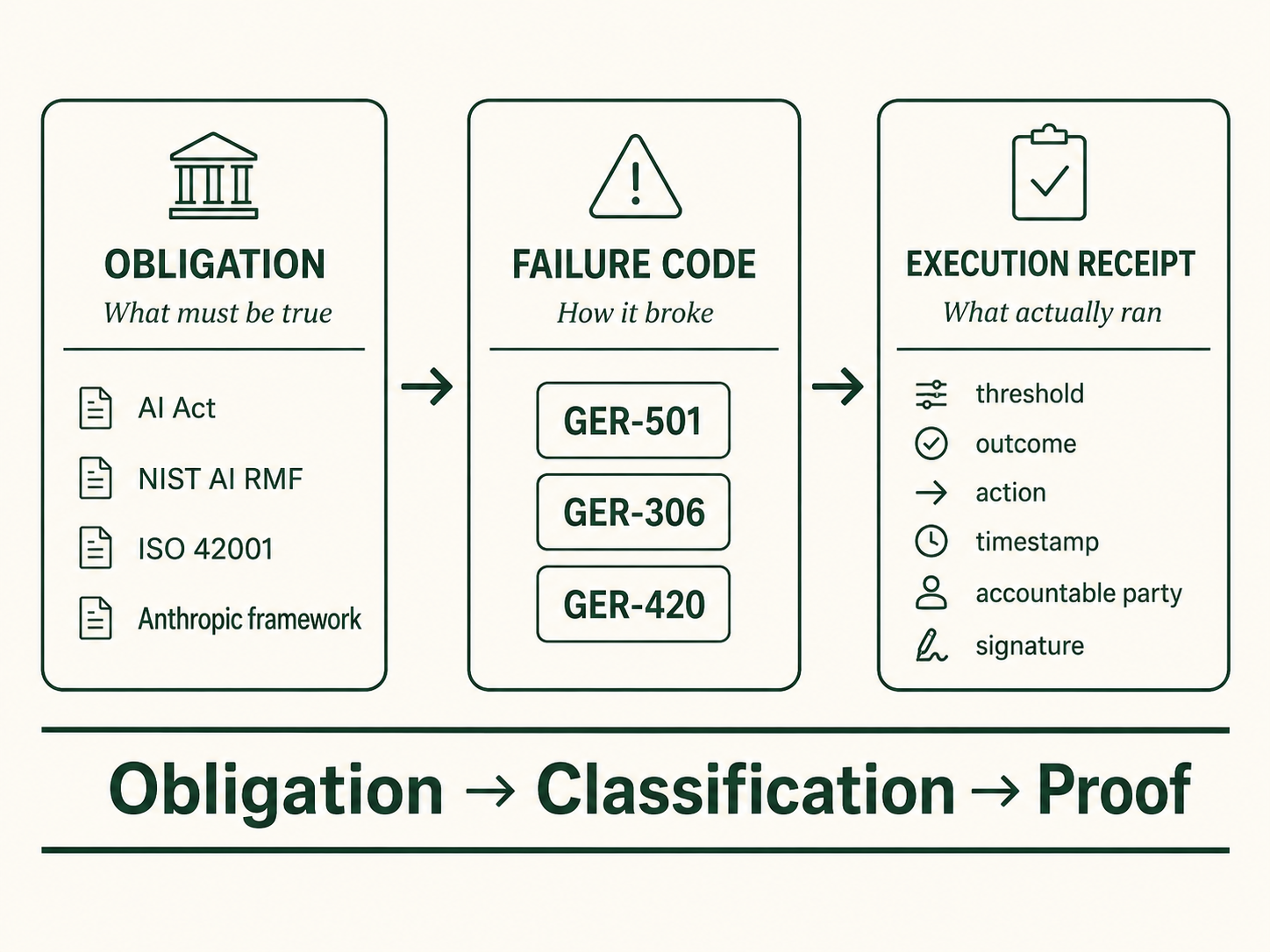
Neither needs to be invented from first principles. Medicine, aviation, and software security wrote the operating pattern decades ago. Candidate AI implementations now exist: an open failure register and a procedural receipt specification, both CC BY 4.0, both published for testing and critique, with named contributors already sharpening them in public. Where did it fail. What was it. Show the log.
The reports are coming either way. The only question is whether anyone can count them.
Both pieces of machinery are published. The Governance Error Register is the codebook: 110 failure codes, CC BY 4.0. The NCSA receipt is the log: signed, procedural, content-free. No permission needed to use either.