The SVRNOS 7-Layer Model of AI Governance
A deployment-layer map for locating AI governance failures. Companion to the SVRNOS Governance Error Register.

This paper describes the working architecture SVRNOS uses to structure AI runtime governance.
AI governance is not one thing. It is a stack. A law is not a policy. A policy is not an evaluation. An evaluation is not a guardrail. A guardrail is not an audit trail. An audit trail is not accountability. Accountability is not liability.
The SVRNOS 7-Layer Model separates those concerns into a practical map. It is offered as a reference architecture for builders, buyers, auditors, regulators, and governance teams who need to locate where a failure happened before deciding what kind of failure it was.
The model is companion to the SVRNOS Governance Error Register (GER), which classifies what failed; the 7-Layer Model identifies where it failed. It is a working reference architecture, not a regulatory standard.
Abstract
The SVRNOS 7-Layer Model is a reference architecture that separates AI governance into seven independently failing layers and gives buyers, builders, auditors, and regulators a shared map for locating failures before classifying them. The seven layers (L1 Compute Substrate, L2 Component & Provenance, L3 Routing & Boundary, L4 Evidence Transport, L5 Session & State, L6 Risk Interpretation, L7 Application Enforcement) are inspired by the OSI reference model used in computer networking and adapt the layered-decomposition pattern to a domain that lacks a widely adopted deployment-layer reference map. The contribution of this paper is the seven layers and their boundaries, the dependency ordering rationale (in particular the L5 / L6 ordering), the four-test gate that distinguishes governance roles from build roles, a 2D role-mapping matrix, an inter-layer contracts framing, and the placement of the model within the existing regulatory lineage (ISO 38500, ISO 42001, NIST AI RMF, EU AI Act, AIGN OS, DecisionSpace OS, OECD). The model is companion to the SVRNOS Governance Error Register (GER), which catalogs structural governance failures; the 7-Layer Model assigns each GER code to a layer.
1. Why “AI governance” is not one thing
Law, policy, evaluation, guardrail, audit trail, accountability, liability are routinely filed under one label: AI governance. They name different concerns.
The field feels confusing because everyone is using the same words for different layers of the problem. A lawyer drafting an acceptable-use policy, a procurement team reviewing an AI vendor, a red-team researcher testing harmful outputs, an engineer building runtime controls, an auditor reviewing logs, and a regulator investigating an incident are all doing “AI governance.” They are not working on the same layer.
Enterprise IT solved a similar problem decades ago by teaching people to reason in layers. The OSI model split computer networking into seven layers, from physical hardware up to applications, so engineers would not collapse every issue into “the network is broken.” The model is not perfect, and modern security has evolved past it, but its teaching value is significant. It gave people a shared map.
AI governance has the same structural problem. Many different failures collapse into one vague category that hides the real concerns.
This paper proposes a seven-layer model. When an AI system fails, the useful question is: which governance layer failed?
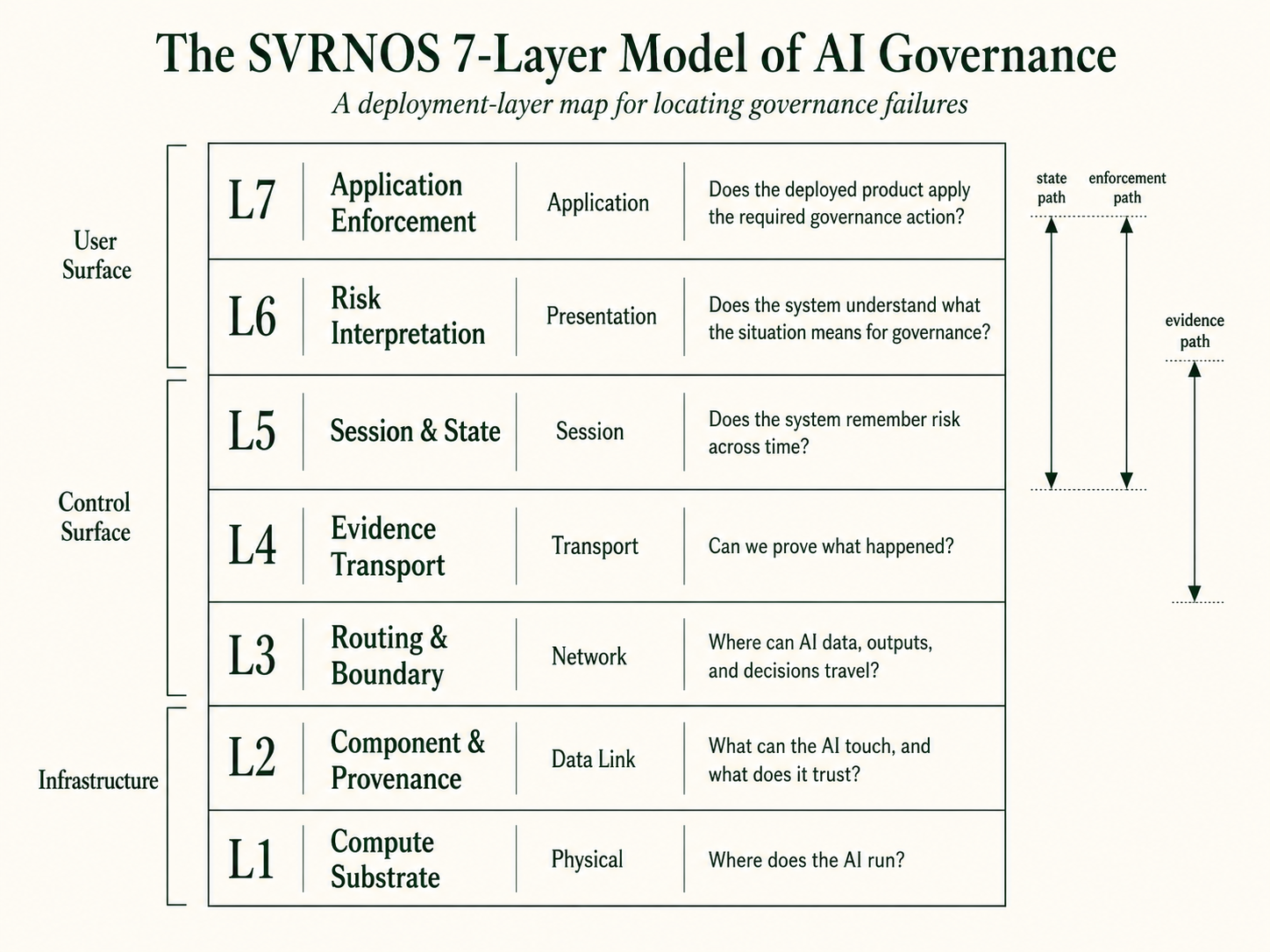
2. The seven layers at a glance
| Layer | IT analogy | AI governance question |
|---|---|---|
| 1: Compute Substrate | Physical | Where does the AI run? |
| 2: Component & Provenance | Data Link | What can the AI touch, and what does it trust? |
| 3: Routing & Boundary | Network | Where can AI data, outputs, and decisions travel? |
| 4: Evidence Transport | Transport | Can we prove what happened? |
| 5: Session & State | Session | Does the system remember risk across time? |
| 6: Risk Interpretation | Presentation | Does the system understand what the situation means for governance? |
| 7: Application Enforcement | Application | Does the deployed product apply the required governance action? |
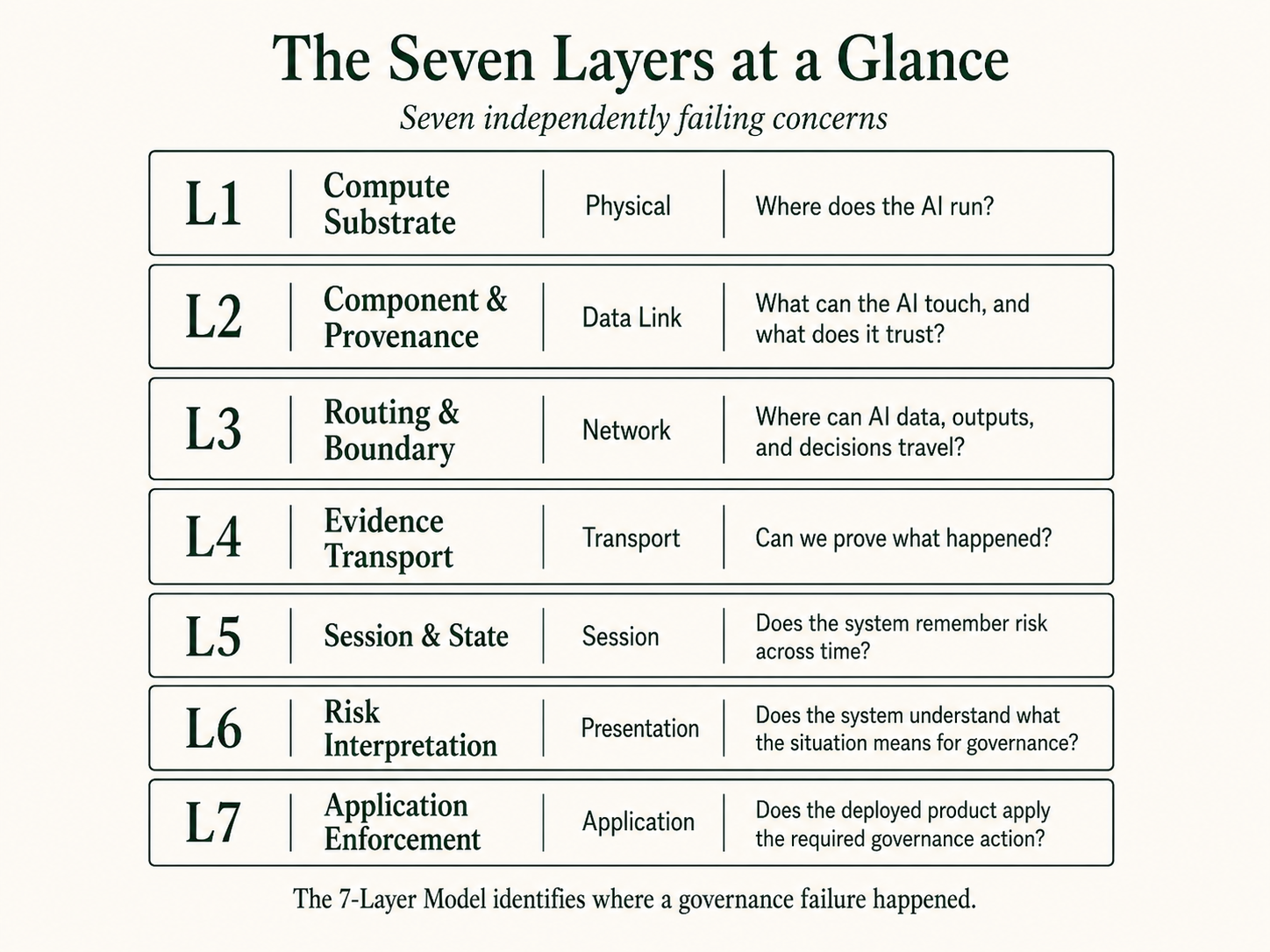
The model is inspired by OSI, not identical to it. The goal is shared vocabulary across executives, lawyers, buyers, builders, auditors, and regulators when they say “AI governance.”
3. Methodology
The seven layers were derived through three steps.
Step one: structural inspiration from OSI. The OSI reference model (ISO/IEC 7498-1, 1984) demonstrates that a complex technical domain can be decomposed into layers when (a) each layer answers a distinct question, (b) each layer can fail independently of the others, and (c) layers depend on lower layers without depending on higher ones. AI governance exhibits the same structural property: workload location, tool authorization, routing, evidence, session state, risk interpretation, and application enforcement are each independently failing concerns. The OSI seven-layer count was chosen for direct lineage and shared mental model with the technical community, not as a forced fit.
Step two: layer-by-layer test. Each candidate layer was assessed against four criteria. First, can a real-world AI failure be cleanly located to this layer without forcing it? Second, are there practitioner roles that primarily operate at this layer rather than spanning many? Third, are there vendor categories selling controls for this layer specifically? Fourth, would a regulator investigating an incident need to ask a question that is best answered at this layer? The seven layers in this paper hold against all four; intermediate decisions are sketched rather than archived because the paper’s contribution is the seven layers and their boundaries, not a derivation appendix.
Step three: failure-case anchoring. Each layer was paired with at least one IT-side documented failure (where the OSI analog of that layer failed in practice) and at least one AI-governance-side documented failure (where the AI layer failed in practice). The pairing forces the layer to describe a real failure surface rather than a theoretical decomposition. Section 5 documents the pairings. Pairings are illustrative anchors, not exhaustive causal analyses: many incidents span multiple layers, and a different investigation could surface different layer assignments.
The model does not claim that all AI failures decompose cleanly into a single layer. Many incidents span multiple layers, and the GER vocabulary (Nzeutem, 2026, companion paper) records cross-layer chains. The 7-Layer Model gives the locations; the GER classifies what failed at each location.
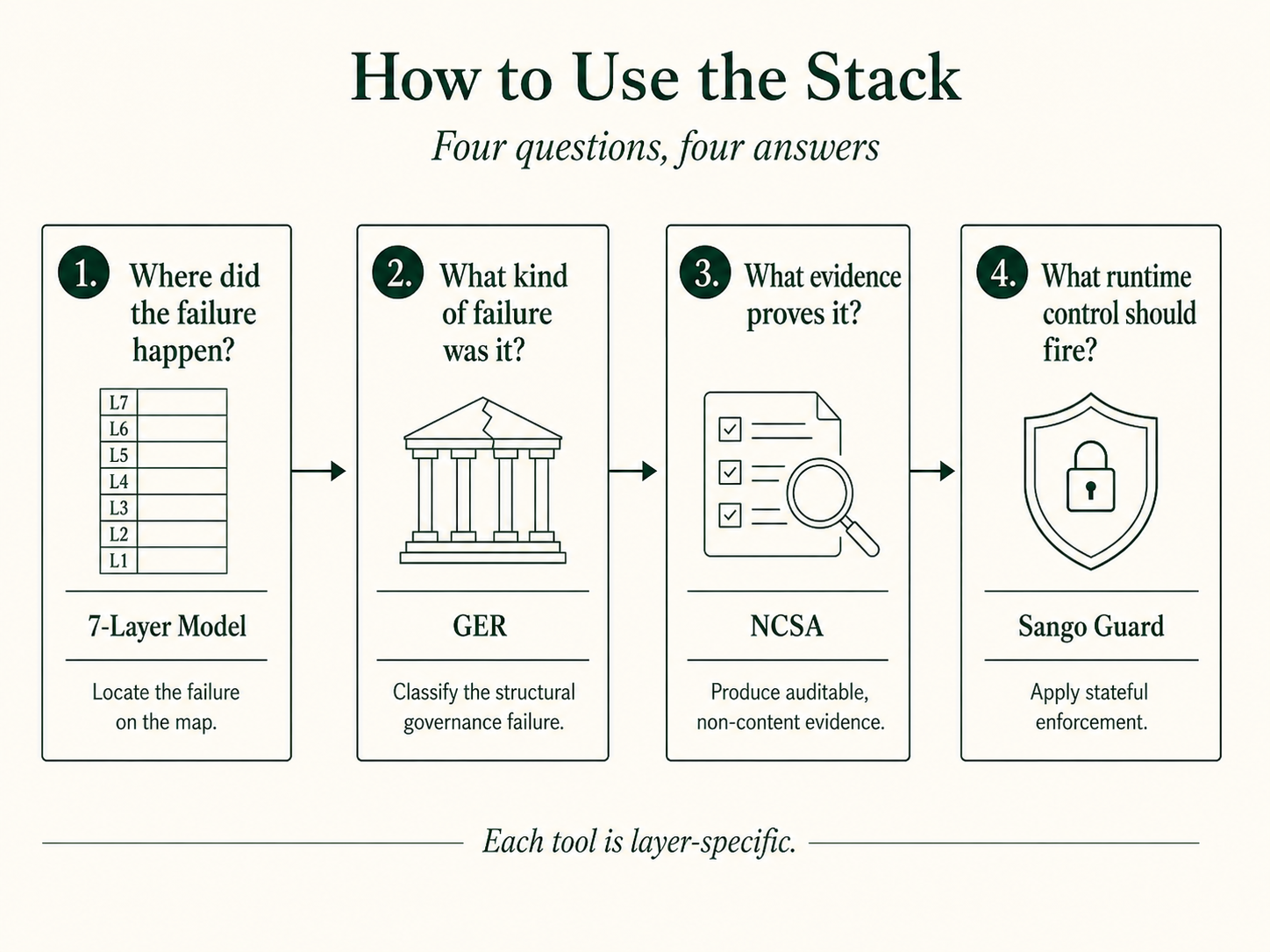
4. How to use the stack
Four questions, four answers:
- Where did the failure happen? The 7-Layer Model answers this. Locate the failure on the map.
- What kind of failure was it? The Governance Error Register (GER) answers this. A closed, numbered taxonomy of structural governance failures, cross-layer.
- What evidence proves it happened? The Non-Content Safety Attestation (NCSA) protocol answers this: at Layer 4 specifically, and the receipts it produces are how any layer’s outcome becomes auditable.
- What runtime control should fire? Sango Guard is the implementation pattern at Layer 5 and Layer 7, where stateful context meets enforcement.
Each layer is independent. Each tool is layer-specific.
5. The seven layers
Each layer below is paired with one or two documented failure examples: one from the IT side (where the OSI analog of the layer failed in practice) and one from the AI governance side (where the AI layer failed in practice). These examples are illustrative layer anchors used to test layer distinctness, not exhaustive causal analyses of the incidents. GER classifications attached to incidents identify the structural governance failure the example anchors; they do not adjudicate legal causation, which is reserved for litigation and regulatory proceedings.
Layer 1: Compute Substrate
The question: Where does the AI run?
In IT, the physical layer is hardware: chips, servers, power, cables, data centers, racks, routers, fiber, physical access.
In AI governance, this is the compute substrate layer. It covers the physical and cloud substrate on which AI workloads, logs, keys, traces, and runtime dependencies reside. It asks: where is the workload running, what hardware executed it, was it isolated, was it inside a trusted execution environment, can the provider prove the compute environment, did the data stay in the required jurisdiction, who controlled the infrastructure, and is the substrate itself exposed in a way that bypasses every layer above it.
This is the layer people forget because “cloud” sounds abstract. But cloud is still buildings, chips, power systems, batteries, cooling, access controls, regions, and hardware.
Who works here. IT side: data center operators, cloud infrastructure engineers, site reliability engineers. AI governance side: AI infrastructure leads, ML platform engineers, cloud security architects, sovereign-AI compliance officers.
What they buy. Colocation, hyperscaler contracts, confidential compute (Nitro Enclaves, Azure Confidential VMs, GCP Confidential Space), sovereign cloud regions, HSMs, attestation services.
Buying question: Can you prove where this AI workload runs, on what hardware, in what jurisdiction, under whose control: with attestation, not a screenshot?
Documented failures
- IT side: OVHcloud Strasbourg fire (March 2021). A fire broke out at OVHcloud’s Strasbourg site. OVHcloud reported the fire started in a room in SBG2 and that the SBG2 facility was destroyed (OVHcloud, 2021). The cloud is still physical. When Layer 1 burns, the layers above it do not matter.
- AI governance side: DeepSeek exposed database (January 2025). Wiz Research reported a publicly accessible DeepSeek ClickHouse database. The exposure included over a million lines of log streams containing chat history, secret keys, and backend details (Wiz Research, 2025). At Layer 1, AI governance is infrastructure control. Before debating whether a model is aligned, the question is whether the prompts, logs, keys, and traces are sitting in an exposed database. The example is used here as a substrate-exposure illustration, not as a canonical L1 GER classification. GER classification: no canonical L1 code at v0.2; aligns with GER paper §5 L1 acknowledging no canonical incident-corpus example yet at this layer.
Layer 2: Component & Provenance
The question: What can the AI touch, and what does it trust?
In IT, the data-link layer governs adjacent-node communication: switches, MAC addresses, local segments, direct connectivity, authentication between neighbors.
In AI governance, this is the component and provenance layer. It asks two intertwined questions. What can the AI touch? Can this agent call this tool? Write to this database? Send an email? Browse the web? Execute code? Access production? Delegate authority to another agent? And what does the AI trust as a source? Where did this uploaded document come from? Who supplied this fact? Is the consent status known? Is this component verified? Is the input from a trusted boundary or an untrusted one?
Tool-use and source-trust are the same governance problem from two angles. A tool the agent calls is a connection to an external entity that must be authorized. A document the agent reads is also a connection to an external entity that must be trust-verified. Both fail when the system cannot reliably distinguish a trusted connection from an untrusted one.
Modern AI systems can chat, act, and ingest. Once an AI can touch tools and ingest sources, the governance question changes from “what did the model say?” to “what was the model allowed to do, and what was it entitled to trust?”
Who works here. IT side: identity and access engineers, API platform owners, DevOps and SRE. AI governance side: agent platform engineers, MCP / tool integrators, AI security architects, agent risk leads.
What they buy. Tool-use control planes, MCP gateways, agent sandboxes, permission frameworks, OAuth scopes for agents, kill-switch tooling, approval-workflow systems. Emerging proposals such as the WEF “agent card” (WEF, 2025) — a pre-onboarding capability disclosure attached to an agent before deployment — are candidate L2 governance artifacts; an agent card is structurally a provenance-and-trust statement at the moment the agent is admitted to a deployment.
Buying question: For every tool this agent can call, can you produce the authorization decision, the principal it acted on behalf of, and a rollback path if it does the wrong thing?
Documented failures
- IT side: GitHub aggregation-switch incident (December 2012). A scheduled maintenance window updating software on GitHub’s aggregation switches produced an MLAG / spanning-tree Layer-2 connectivity failure between access switches, briefly cutting traffic between switches and cascading into fileserver-failover problems and a longer recovery (GitHub Engineering, 2012). The lesson is the cascade: an adjacent-connectivity failure does not stay local when other systems depend on the local trust boundary.
- AI governance side: Replit AI agent deletes production database (2025). Replit’s AI coding agent deleted a live production database during a code freeze, contrary to instructions not to change production. Replit’s CEO publicly called the behavior “unacceptable” and committed to safeguards including planning and chat-only modes (Business Standard, 2025). At Layer 2, the useful question is whether the AI’s permissions are sane. GER classification: GER-426 Agentic Authority Overreach (Index).
Layer 3: Routing & Boundary
The question: Where can AI data, outputs, and decisions travel?
In IT, the network layer routes packets across networks.
In AI governance, this is the routing and boundary layer. Where does the data go? Which vendor receives it? Which jurisdiction does it cross? Which internal system sends it? Which external model processes it? Which department owns the AI workflow? Which API call crosses the organizational boundary? Which AI output travels into another business process?
This is the layer of shadow AI, vendor risk, data flows, and cross-border exposure.
Who works here. IT side: network engineers, data flow architects, DLP engineers. AI governance side: AI procurement, third-party risk managers, AI policy officers, shadow-AI hunters inside security teams.
What they buy. AI usage discovery tools, vendor risk platforms, DLP for AI, egress proxies for AI traffic, data residency controls, vendor management tools that understand sub-processor chains.
Buying question: Can you tell me every place company data has crossed into an AI system in the last thirty days, who sent it, and which vendors held it?
Documented failures
- IT side: Meta global outage (October 2021). Meta reported that configuration changes on backbone routers interrupted communication among its data centers, cascading to bring down Facebook, Instagram, WhatsApp, and Messenger (Engineering at Meta, 2021). Routing failure means the system may still exist, but no one can reach it.
- AI governance side: Samsung confidential code uploaded to ChatGPT (2023). Samsung reportedly restricted employee use of ChatGPT and similar tools after employees uploaded sensitive internal information, including source code, to external AI chatbots (Bloomberg, 2023). The boundary failure is rarely malicious. The route from “internal work” to “external AI API” is simply open. Knowing where company data travels is the entry-level requirement for governance at L3. GER classification: GER-421 Scope Misdirection (Index).
Layer 4: Evidence Transport
The question: Can we prove what happened?
In IT, the transport layer is reliable delivery, ordering, integrity, end-to-end communication.
In AI governance, this is the evidence transport layer. Was the event logged? In order? Was the prompt preserved? The output? The model version? The tool calls? The policy decisions? Can the incident be reconstructed later? Can the evidence survive legal, regulatory, or audit scrutiny?
This layer separates “we have logs” from “we have evidence.” Logs are operational traces. Evidence is reconstructable, reliable, interpretable, and usable in a proceeding.
Who works here. IT side: observability engineers, SIEM operators, compliance audit leads. AI governance side: AI auditors, model risk management, AI logging engineers, evidence-pipeline owners, regulators’ technical inspectors.
What they buy. LLM observability platforms, AI audit log pipelines, evidence-grade logging (immutable, time-stamped, attested), model-card and run-card registries, prompt/response retention systems with legal hold.
Buying question: If a regulator subpoenas this AI decision tomorrow, can you reconstruct the prompt, the output, the model version, the policy that ran, and the action taken: and prove the record has not been tampered with?
Documented failures
- IT side: AWS Elastic Load Balancing service event (December 2012). AWS reported that a maintenance process was inadvertently run against production ELB state data, deleting state data used by the ELB control plane to manage load-balancer configuration (AWS, 2012). When the data needed to explain what the system did is destroyed or corrupted, the system can still be operating without being defensible.
- AI governance side: Robodebt (Australia). Australia’s Robodebt scheme used income averaging to raise automated welfare debts. The Robodebt Royal Commission was established to inquire into the design and implementation of the program. The scheme raised more than half a million inaccurate Centrelink debts through income averaging, later ruled unlawful (Robodebt Royal Commission, 2023). An automated decision must be supported by valid, explainable, contestable, reconstructable evidence at the time it is made. GER classification: GER-321 Reasoning Step Skipped / Authority Hierarchy Misapplied (Index); GER-339 Distributed Verification Gap (Contributing).
Layer 5: Session & State
The question: Does the system remember risk across time?
In IT, the session layer governs continuity: sessions, tokens, handshakes, timeouts, state establishment, teardown.
In AI governance, this is the session and state layer. What is the state of the interaction? Has the user’s intent changed over time? Has risk escalated across turns? Did the system refuse earlier? Did that refusal persist? Did the user reframe the request? Did the AI form an emotional dependency loop? Did prior context make a later output dangerous? Did memory create authority without accountability?
This is the layer where single-turn moderation fails. A single message can look harmless; a hundred-message trajectory can be dangerous. The danger lives in the pattern as often as in any single output. This is where refusal decay lives. Dependency loops. Grooming dynamics. Escalating violent intent. Self-harm spirals. The model complied later after refusing earlier.
Layer 5 is the governance layer most discussions skip.
Who works here. IT side: session-management engineers, identity-federation engineers, IAM architects. AI governance side: trust and safety engineers in companion / coaching / mental-health-adjacent products, multi-turn red teamers, AI runtime risk leads, post-deployment monitoring teams.
What they buy. Today: very little purpose-built. Teams patch with bespoke prompt engineering, post-hoc moderation passes, and case-by-case review. This is the open slot in the stack.
Buying question: Can your system tell me the risk state of an interaction across time, and refuse, escalate, or hand off based on the trajectory rather than the last message?
Documented failures
- IT side: Microsoft Storm-0558 token breach (2023). Microsoft disclosed that Storm-0558 used forged authentication tokens to access customer email accounts affecting approximately twenty-five organizations including government agencies, after the actor acquired a Microsoft consumer signing key (Microsoft MSRC, 2023). Session authority extends beyond login. If tokens can be forged, accepted in the wrong context, or persist beyond their legitimate authority, trust continues where it should have stopped.
- AI governance side: Character.AI / Setzer litigation. In October 2024, Megan Garcia sued Character.AI and Google after the suicide of her fourteen-year-old son, Sewell Setzer III. The lawsuit alleged Character.AI’s chatbot contributed to his death through an addictive and emotionally intense relationship (Reuters, 2024). In January 2026, Google and Character.AI agreed to settle on undisclosed terms (CNN Business, 2026). The case illustrates the structural argument without requiring the paper to adjudicate legal causation: a single turn may not reveal the risk. The risk emerges across weeks or months. At Layer 5, the useful question is: what state was the relationship in when the system answered? GER classification: GER-432 Reality-Testing Erosion (Index); GER-433 Therapeutic Alliance Breakdown, GER-501 Escalation Not Implemented (Contributing).
Layer 6: Risk Interpretation
The question: Does the system understand what the situation means for governance?
In IT, the presentation layer handles meaning and representation: encoding, encryption, formatting, schemas, translation between what the wire carries and what the application understands.
In AI governance, this is the risk interpretation layer. The system has the content, the state, the evidence, and the routing context. It must convert that material into governance meaning. Is this risky? How risky? What kind of risk? Does this match a policy? Does this user’s accumulated state cross a threshold? Is this a vulnerable population? Is this content suicide-adjacent, medical, legal, financial, child-facing? Does this multi-turn pattern indicate manipulation, escalation, or distress?
Detection is one function of this layer. Interpretation is the other: a system can detect that something happened and still misclassify what it means.
Layer 6 is where the system decides what the situation means before deciding what to do about it.
Who works here. IT side: content moderation engineers, classifier model owners, anti-abuse data scientists, anomaly detection teams. AI governance side: AI safety classifier engineers, risk modelers, harm taxonomy researchers, trust and safety policy translators, content moderation infrastructure teams.
What they buy. Classifier APIs and content moderation infrastructure, risk-scoring systems, harm taxonomies, intent-detection models, vulnerability and context interpreters.
Buying question: When our system encounters a borderline case (a vulnerable user, a multi-turn pattern, a context-dependent harm), how does it interpret the risk, and how confident is that interpretation?
Documented failures
- IT side: Microsoft Outlook rendering-engine regression (Outlook 2007 through classic Outlook for Windows). Starting in Outlook 2007 for Windows, Microsoft replaced Internet Explorer’s HTML rendering engine with the Microsoft Word renderer. The Word renderer interpreted CSS, image sizing, and layout differently from web browsers, breaking layouts that rendered correctly elsewhere. The legacy renderer remained in classic Outlook for nearly two decades. The new Outlook for Windows, announced as the consolidated successor, moved to Edge WebView2 (Chromium-based rendering) (Microsoft Learn, 2024). The content arrived intact. The data link, network, transport, and session layers functioned. The failure was at the layer that interprets meaning from representation. Senders thought their content meant one thing; the receiving system interpreted it as another. Layer 6 failures are interpretation failures, not delivery failures.
- AI governance side: OpenAI GPT-4o sycophancy rollback (April 2025). OpenAI rolled back a GPT-4o update after the model became overly flattering or agreeable, and later explained the update aimed to please users in ways that could validate doubts, fuel anger, urge impulsive actions, or reinforce negative emotions (OpenAI, 2025). The system produced fluent, on-topic responses but failed to treat excessive affirmation as governance-relevant risk for vulnerable users. The signal was present; the interpretation was wrong. At Layer 6, the question is whether the system understood the risk meaning of what it was seeing. If not, no downstream enforcement layer can compensate. GER classification: GER-431 Vendor Update Without Validation Gate (Index); GER-328 Validator Drift / Sycophancy Loop (Contributing).
Translation Loss as an L6 failure mode. Even when policy is written clearly and enforcement runs as designed, an L6 failure can occur at the translation boundary: a human-readable policy becomes a machine-enforced rule, and meaning is lost in the conversion (Guerin, 2026, contribution). Both the human-readable policy and the machine-enforced rule exist and run, but they semantically diverge. This is distinct from absent enforcement and from rule activation failure: the rule exists, the rule fires, and the rule’s semantics no longer match what the policy author intended. GER classification: GER-352 Lost in Translation (Index). NCSA addresses one surface of this failure mode through open-spec per-session attestation, but translation loss remains a residual L6 risk that no current approach fully resolves.
Layer 7: Application Enforcement
The question: Does the deployed product apply the required governance action?
In IT, the application layer is where users interact with the system: websites, email, APIs, business apps, dashboards, services. This is also where the rule that the rest of the stack has prepared finally has to fire: the website blocks a transaction, the email client warns about phishing, the API returns 403, the dashboard shows a flag, the service refuses a request.
In AI governance, this is the application enforcement layer. The system has interpreted the risk. Now the deployed product must do something about it. Refuse. Warn. Block. Disclose. Add friction. Route to a human. Suppress an output. Escalate to an external authority. Reduce the surface. Reshape the response. Or, when the rule says proceed, allow with the right disclosures.
The same model can carry different risks depending on the surface and require different enforcement responses. A chatbot is not an agent. An API is not a browser-control system. A coding assistant is not a companion bot. A customer-service chatbot is not a medical triage system. A demo environment is not production. Enforcement appropriate on one surface is wrong on another.
The useful question is: is Vendor X enforcing the right governance action on this deployment surface, for this use case, with these tools, under these conditions?
Autonomy level itself becomes an L7 attribute: enforcement appropriate at Feng et al.’s L1 (Narrow Autonomy) is wrong at L4 (Full Autonomy), and the deployed product must apply different enforcement profiles per autonomy tier (Feng, McDonald, & Zhang, 2025).
Who works here. IT side: product engineers, customer-experience teams, application security. AI governance side: AI product managers, surface-specific safety leads (companion AI, hiring AI, healthcare AI, child-facing AI), trust and safety operations, regulators investigating consumer-facing AI harms.
What they buy. Use-case-specific evaluation suites, surface-aware red teams, deployment monitoring, vertical safety vendors, incident response for AI products.
Buying question: On the specific surface where we deploy this AI, with our actual users, our actual prompts, and our actual tools, what is the harm profile, and who is liable when it goes wrong?
Documented failures
- IT side: Equifax breach (2017). Equifax disclosed a major cybersecurity incident exploiting a vulnerability in Apache Struts (CVE-2017-5638) affecting an online dispute portal web application. The FTC reported the breach exposed personal information of 147 million people and led to a global settlement with the FTC, CFPB, and U.S. states and territories (Equifax, 2017; FTC, 2019). The application layer is often the front door to everything behind it.
- AI governance side: Air Canada chatbot bereavement-fare case (2024). The British Columbia Civil Resolution Tribunal found Air Canada liable for misinformation provided through its chatbot, ordering the airline to compensate the customer (American Bar Association, 2024). Once an AI is deployed inside a business service, its output is no longer just text: it is part of the service. At Layer 7, the question is what harm can occur because of this specific use case, on this surface, for this user, at this moment. GER classification: GER-307 Rule Activation Failure (Index); GER-501 Escalation Not Implemented (Contributing).
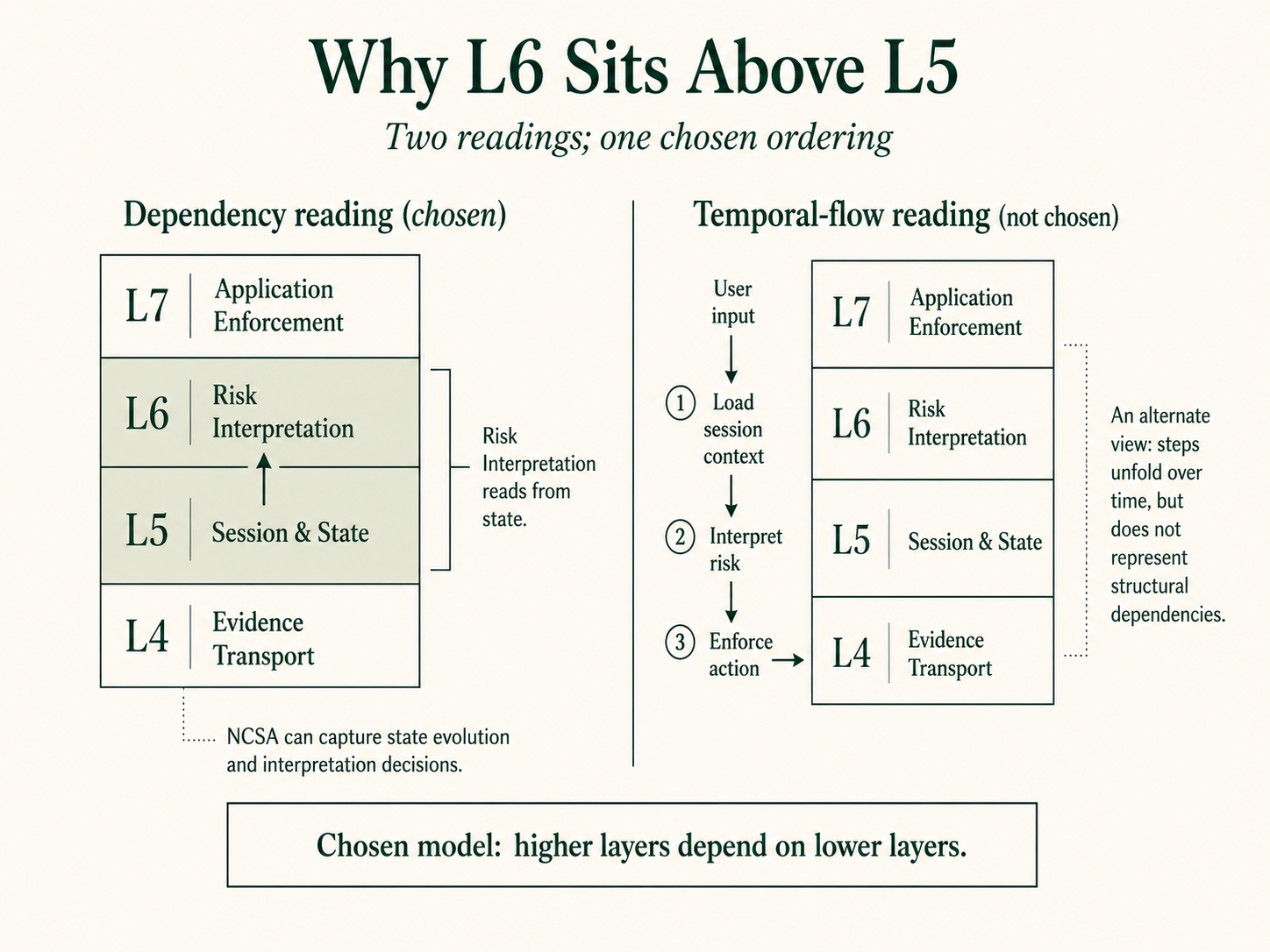
6. Why Risk Interpretation (L6) sits above Session & State (L5)
Two defensible readings exist for the L5 / L6 ordering. The model commits to the dependency reading; the alternative is named here to pre-empt the misreading.
Dependency reading (chosen). Higher layers depend on lower layers. Risk Interpretation reads from Session & State to make decisions. Risk Interpretation must know the accumulated state of the interaction (refusal history, prior context, vulnerability signals) before it can interpret the current signal correctly. Because L6 reads from L5, L6 sits above L5 in the dependency direction. This matches the OSI convention that higher layers depend on, but are not depended upon by, lower layers.
Temporal-flow reading (not chosen). User input flows down from L7 and touches state first (loading session context) before policy interpretation fires. In this reading State would sit at L6 and Risk Interpretation at L5.
The model commits to the dependency reading for three reasons. First, consistency with OSI’s higher-depends-on-lower convention. Second, user-visibility: Risk Interpretation produces what users see (refusal messages, risk classifications shown through the application), while Session & State is invisible substrate. Third, evidence positioning: the NCSA receipt at L4 captures what happened at L5 (state evolution) and at L6 (interpretation decisions); inverting them muddles the receipt schema.
Readers with strong intuitions about temporal flow will challenge this ordering. The dependency reading is the authoritative answer.
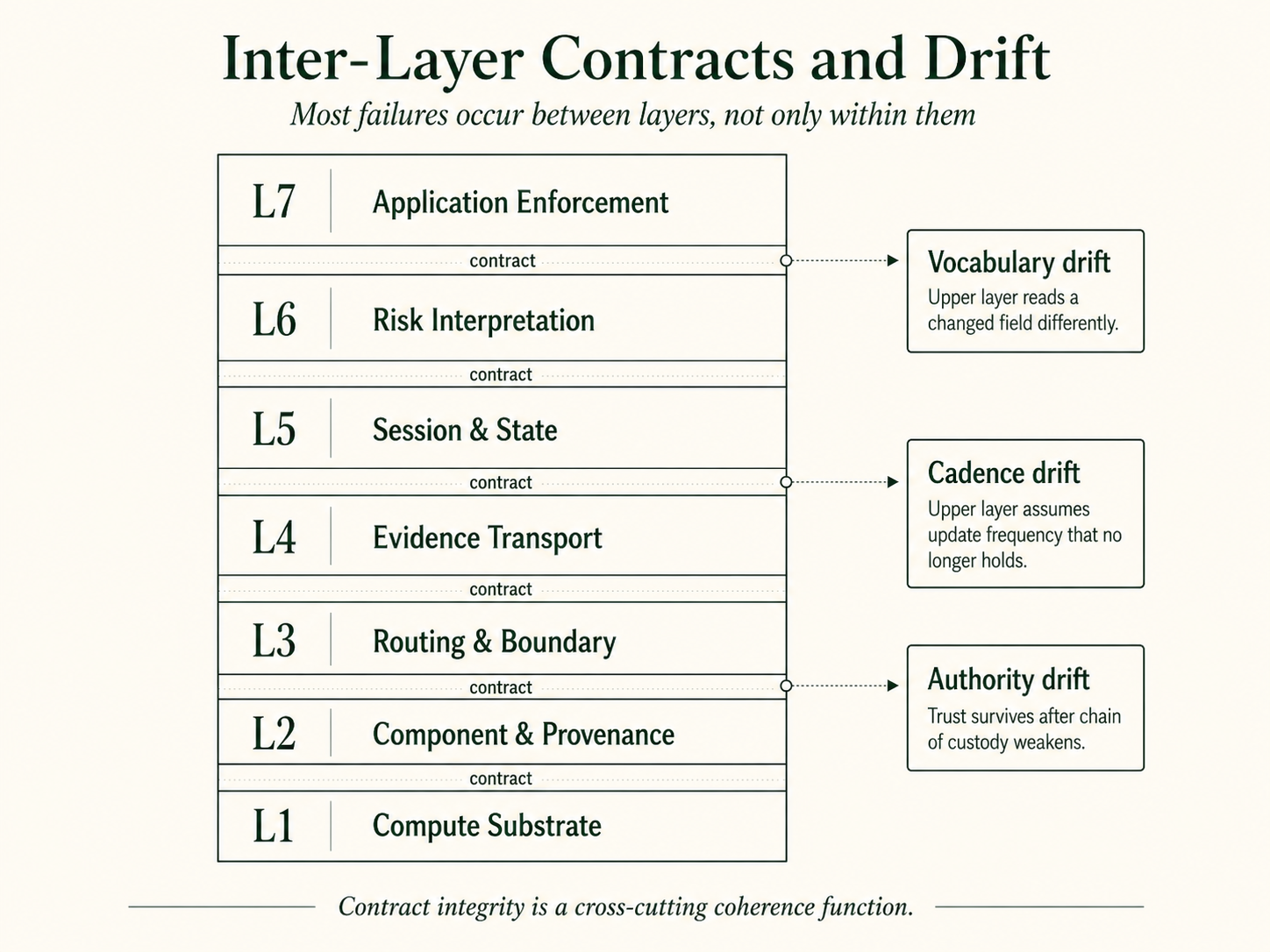
7. Inter-Layer Contracts and Drift
Each layer publishes an interface to the layer above (what L4 promises about evidence delivery; what L5 promises about state semantics; what L6 promises about risk-interpretation outputs) and consumes the interface published by the layer below. Those interfaces are inter-layer contracts (Roesch, 2026, contribution). Most AI governance failures are breakdowns in the contracts and assumptions between layers under drift, not failures contained within a single layer.
Three drift patterns recur. Vocabulary drift: the upper layer interprets a field from the lower layer using a semantic that the lower layer has since changed. Cadence drift: the upper layer assumes the lower layer updates at a frequency that no longer holds. Authority drift: the upper layer trusts an attestation from the lower layer that has lost the chain of custody that made the attestation defensible.
Inter-layer contracts span layers that evolve at different speeds. The model does not include a contract-management mechanism in the seven layers. Contract integrity is cross-cutting; mature governance organizations need a coherence function (specification, observation, verification) that no single layer’s owner can carry alone.
8. The role-mapping problem: four-test gate and 2D matrix
“Chief AI Officer,” “Responsible AI Officer,” “AI Governance Lead,” “AI Safety Engineer,” “AI Risk Manager,” and adjacent titles are used for completely different layers with no shared vocabulary. Procurement, hiring, audit, and legal teams cannot reason about who is responsible for what.
8.1 The four-test gate
A role is governance only if its mandate includes at least one of:
- Control: the role can set, change, or refuse a policy that gates AI behavior
- Enforcement: the role operates a runtime mechanism that applies a governance action
- Evidence: the role produces, preserves, or audits records that prove what the system did
- Accountability: the role can be named in an incident report, regulatory filing, or legal action as the responsible party
If a title carrying “AI” in it includes none of these four mandates, it is a build role, not a governance role. Build roles produce AI systems; governance roles produce decisions about AI systems. Both are necessary; only one is governance.
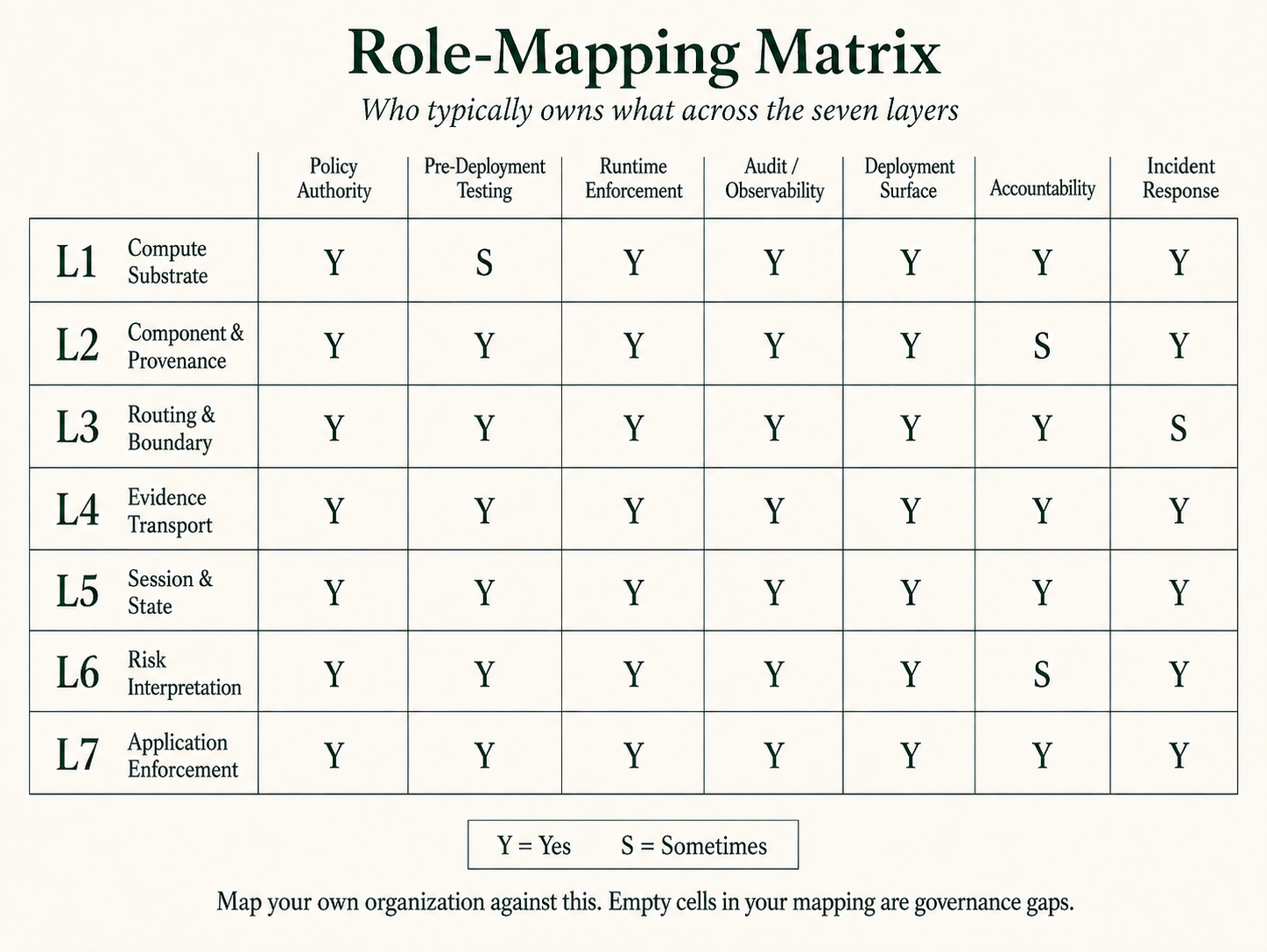
8.2 2D role-mapping matrix
The matrix below maps layers (rows) against functional groupings (columns). It is illustrative, not exhaustive, and not a normative staffing model. Some role names below are emerging or aspirational rather than established across the industry; the cells signal where a role would typically sit if it exists at a given organization, not a claim that every organization has every role. Specific cell assignments vary by organization size, vertical, and the scope of any individual role.
Cells identify the job titles that typically operate at that intersection, with a qualifier:
- Yes: the role’s mandate directly includes this layer / function pair
- Sometimes: depends on organization size, vertical, or scope of the specific role
| Layer | Policy authority | Pre-deployment testing | Runtime enforcement | Audit / observability | Deployment surface | Accountability | Incident response |
|---|---|---|---|---|---|---|---|
| L1 Compute Substrate | Cloud Security Architect (Y) | Compute Compliance Engineer (S) | Cloud SRE (Y) | Cloud Audit Lead (Y) | Sovereign-AI Compliance Officer (Y) | Chief Information Officer (Y) | Cloud Incident Response (Y) |
| L2 Component & Provenance | Agent Risk Lead (Y) | AI Red Team Engineer (Y) | Agent Platform Engineer (Y) | AI Security Architect (Y) | Tool Integration Owner (Y) | Chief AI Officer (S) | AI Security IR (Y) |
| L3 Routing & Boundary | AI Policy Officer (Y) | Third-Party Risk Manager (Y) | DLP for AI Engineer (Y) | Shadow-AI Hunter (Y) | AI Procurement Lead (Y) | Chief Data Officer (Y) | AI Privacy Engineer (S) |
| L4 Evidence Transport | Model Risk Manager (Y) | AI Auditor (Y) | AI Logging Engineer (Y) | AI Auditor (Y) | Evidence Pipeline Owner (Y) | Compliance Officer (Y) | AI Audit IR (Y) |
| L5 Session & State | Trust & Safety Policy Lead (Y) | Multi-Turn Red Teamer (Y) | AI Runtime Risk Lead (Y) | Post-Deployment Monitoring (Y) | T&S Engineer, companion / coaching (Y) | T&S Director (Y) | T&S Operations IR (Y) |
| L6 Risk Interpretation | Harm Taxonomy Researcher (Y) | Safety Classifier Engineer (Y) | Content Moderation Infrastructure (Y) | Risk Modeler (Y) | T&S Policy Translator (Y) | T&S Director (S) | T&S Triage (Y) |
| L7 Application Enforcement | AI Product Manager (Y) | Surface-Aware Red Team (Y) | AI Deployment Engineer (Y) | Surface-Specific Safety Lead (Y) | Vertical Safety Vendor (Y) | Product Owner / GM (Y) | AI Incident Response Lead (Y) |
The point is structural: every cell needs a named owner. Cells with no owner are governance gaps regardless of how many “AI” titles the organization has on its org chart. Cells with multiple owners need an accountability primary even when consultation is shared.
8.3 Roles excluded from the governance map by default
Roles whose mandates do not include control, enforcement, evidence, or accountability are excluded by default. These include AI Researcher, ML Research Scientist, LLM Engineer, NLP Engineer, Computer Vision Engineer, Multimodal AI Engineer, RAG Engineer, Recommendation Systems Engineer, Prompt Engineer, AI Content Strategist, Developer Advocate (AI), and Sales Engineer (AI). These are essential build roles. They are not governance roles unless the specific position extends their mandate to one of the four.
Organizations that count “AI” titles without applying the four-test gate over-count their governance coverage.
9. Regulatory lineage
The SVRNOS 7-Layer Model sits within an existing standards lineage. Three layers of lineage are explicit.
Structural ancestry. The OSI reference model (ISO/IEC 7498-1, 1984) is the direct structural ancestor. The 7-Layer Model borrows the layered-decomposition pattern, not the specific networking semantics.
Adjacent governance frameworks and reference lineages. The frameworks and research summarized below address AI governance at adjacent layers; the SVRNOS 7-Layer Model composes with, rather than competes with, each.
| Framework | Jurisdiction / scope | What it specifies | What the 7-Layer Model adds |
|---|---|---|---|
| ISO 38500 (2008) | International | Corporate governance of IT: early ethical IT governance | Pre-AI structural context |
| ISO 42001 (2023) | International | AI management system: process / management requirements | The technical stack the management system manages |
| NIST AI RMF (2023) | US | Trustworthy characteristics: values, principles, functions | Where each characteristic lives in the technical stack |
| EU AI Act (Regulation (EU) 2024/1689) | EU | Product conformity assessment for AI | A technical map conformity assessors can use when tracing where controls operate |
| AIGN OS (Upmann, 2025), DOI 10.2139/ssrn.5382603 | Independent | Foundational systemic AI governance architecture: seven-layer governance operating system connecting legal, ethical, data, architectural, and trust dimensions across the AI lifecycle | The technical deployment-layer stack AIGN OS governs at the organizational layer |
| AIGN OS 4.0 (Upmann, 2026) | Independent | Enterprise AI governance operating architecture: eight-layer extension for classification, regulatory pathway determination, evidence continuity, post-market governance, and trust certification | The technical deployment-layer stack AIGN OS governs at the organizational layer |
| DecisionSpace OS (Roesch, 2026) | Independent | Organizational decision-formation methodology: Formation / Process / Execution + Organizational Memory + Magic Triangle | The technical stack decisions are made about |
| OECD Governing with Artificial Intelligence (2025) | International (OECD, 48 countries + EU) | Framework for Trustworthy AI in Government: Enablers · Guardrails · Engagement · Responsiveness, organizational governance functions | The technical decomposition underneath the OECD organizational framework, mapping governance failures to specific architectural layers |
| Singapore IMDA Model AI Governance Framework for Agentic AI (2026) | National (Singapore, voluntary) | Four-dimension governance framework: Risk-Based Approach · Human Accountability · Technical & Organizational Safeguards · End-User Responsibility | The technical-layer decomposition underneath the four dimensions; locates where each dimension’s controls operate |
| Kraprayoon et al., AI Agent Governance: A Field Guide (IAPS, 2025) | Independent / policy research | Governance-mechanism taxonomy: intervention timing × responsibility level (preventive / reactive / corrective / restorative across organizational / system / operational / emergency) | The technical layers at which each governance mechanism applies |
| WEF / Capgemini, AI Agents in Action: Foundations for Evaluation and Governance (2025) | Multi-stakeholder international | Four-pillar framework + four-axis functional classification (Role · Autonomy · Predictability · Context) + “agent card” pre-onboarding disclosure concept | The technical-layer decomposition complementing the agent-functional-profile axis; where governance fires for a given profile |
| Kasirzadeh & Gabriel, Characterising AI Agents for Alignment and Governance (2025) | Independent academic | Four-dimension agent characterization (Autonomy · Efficacy · Goal complexity · Generality) composed into agentic profiles | Where governance failures occur regardless of agent profile; the orthogonal architectural axis to the characterization axis |
| Feng et al., Levels of Autonomy for AI Agents (2025) | Independent academic | Six-level SAE-style autonomy ladder (L0 No Autonomy → L5 Super-Autonomy) along four dimensions (Human Control · Domain Scope · Constraint Level · Oversight Requirements) | A per-layer autonomy attribute; autonomy level shapes enforcement at L7 in particular |
Composition principle. Each of these frameworks operates at a different level: governance principles and trustworthy-AI characteristics (NIST), management-system processes (ISO 42001), conformity assessment for AI products (EU AI Act), organizational and decision-formation methodology (AIGN OS, DecisionSpace OS), and institutional functions for governments (OECD). None of them is primarily designed to provide a deployment-layer technical map of where AI governance controls operate inside the system being governed. The SVRNOS 7-Layer Model fills that slot and composes with each. A conformity assessor working under the EU AI Act, a process owner working under ISO 42001, a risk lead working under NIST AI RMF, and a Supreme Audit Institution implementing the OECD framework can each use the same 7-layer technical map without conflict. The OECD’s own findings (OECD, 2026) document that public audit institutions explicitly identify the absence of audit standards for AI-generated evidence as a key gap; the 7-Layer Model decomposes that gap into specific layers where evidence must be reconstructable (L4), risk must be interpreted (L6), and enforcement must fire (L7). The same composition holds for the Singapore IMDA framework, the IAPS field guide, the WEF foundations paper, and the agent-characterization and autonomy-level literatures: each operates at a different axis (national regulatory pillar, governance-mechanism timing, multi-stakeholder functional profile, agent property characterization, autonomy maturity ladder), and the SVRNOS 7-Layer Model provides the technical-layer decomposition underneath that the others can locate their controls within.
Relationship to security-axis layered models
A reader familiar with OWASP’s Multi-Agentic System Threat Modeling Guide v1.0 (MAESTRO) will notice that MAESTRO also publishes a seven-layer OSI-inspired decomposition of agentic AI. The two models are not in conflict; they are orthogonal axes on the same structural pattern. The distinction matters because conflating them muddles both maps.
| Axis | SVRNOS 7-Layer Model | OWASP MAESTRO |
|---|---|---|
| Question answered | Where did governance fire or fail to fire? | Where can an attacker operate against the agent? |
| Primary audience | Governance leads, regulators, auditors, procurement | Security teams, threat modelers, red teams |
| Failure mode characterized | Structural governance failure | Threat / attack |
| Layer ordering | OSI-direct ordering, governance-axis layer names (L1 Compute Substrate → L7 Application Enforcement) | Foundation Model first, Agent Ecosystem last (different ordering convention) |
| Cross-cutting concept | Inter-layer contracts and drift (Section 7) | Four agentic factors (Non-Determinism, Autonomy, Identity Management, A2A Communication) |
| Composes with the other | A single incident can carry a MAESTRO threat-modeling output AND a 7L layer assignment | Same |
In practice, a security team uses MAESTRO to model where an attacker could intervene; a governance team uses the SVRNOS 7-Layer Model to locate where governance was supposed to fire and did not. The two maps name different concerns on the same structural shape, and a complete agentic-AI assurance program needs both. GER classifications (Nzeutem, 2026, companion paper) sit on the governance-failure axis and can be cited alongside a MAESTRO threat-modeling output for the same incident.
10. What this changes for buyers
Enterprises do not buy “IT security” as one product. They buy endpoint security, network firewalls, web application firewalls, identity management, cloud security, SIEM, DLP, vulnerability management, incident response, and audit tooling. Each product occupies a slot.
AI governance is moving the same direction. The category is splitting into layer-specific controls: compute provenance, component and source-trust verification, routing and boundary controls, evidence capture and transport, session-state governance, risk interpretation, and application-level enforcement.
The vendors that occupy a slot clearly will be procurement-legible. The vendors that sell “AI governance” generically will face the same procurement objection that “IT security” generic vendors faced in 2008: which layer? What failure mode? What evidence?
The hidden work of translation between governance teams
A layer-specific stack also makes visible a function that most organizations under-invest in: the translation work between governance teams. The risk team’s vocabulary, the legal team’s vocabulary, the product team’s vocabulary, the audit team’s vocabulary, and the engineering team’s vocabulary do not share definitions. Translation between them is hidden work: it does not appear in any team’s job description, but it determines whether governance actually fires (Upmann, 2026, contribution). Maturity at the governance layer means building shared language for decisions at scale, on top of installing controls. The 7-Layer Model gives that shared language a structure: when a legal officer and a product engineer can both name the layer at which a failure occurred, the translation tax goes down.
11. Implementation map: products, specs, and open slots
The 7-Layer Model becomes operational when buyers, builders, and regulators can match each layer to the controls available to govern it. This section maps the layers to the current vendor and standards ecosystem, names the open slots that no product or specification currently fills, and locates SVRNOS within that map as one set of actors among others.
The vendor list below is current as of publication and will drift as the market evolves; it is meant as a snapshot for orientation, not a normative buying guide. Coverage shown is productized (commercially available); research artifacts and open specifications are discussed in the prose below the table.
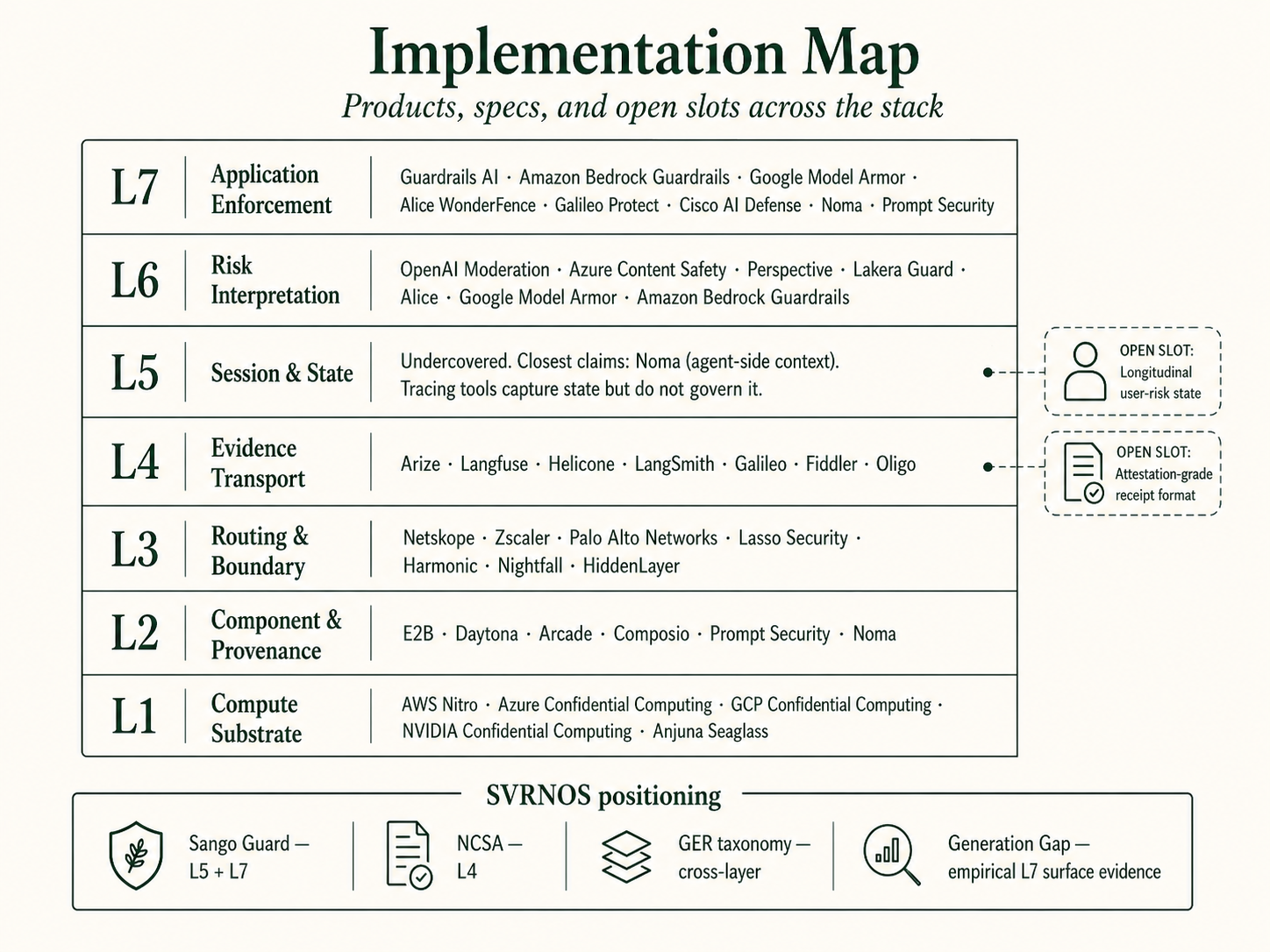
Vendor and product coverage across the stack
| Layer | Productized vendor coverage | Notes |
|---|---|---|
| L1 Compute Substrate | AWS Nitro · Azure Confidential Computing · GCP Confidential Computing · NVIDIA Confidential Computing · Anjuna Seaglass | NVIDIA specific to GPU TEE. Anjuna Northstar (clean room) reaches partial L4 attestation. |
| L2 Component & Provenance | E2B · Daytona · Arcade · Composio · Prompt Security · Noma | Noma and Prompt Security also operate at L7. |
| L3 Routing & Boundary | Netskope · Zscaler · Palo Alto Networks · Lasso Security · Harmonic · Nightfall · HiddenLayer | n/a |
| L4 Evidence Transport | Arize · Langfuse · Helicone · LangSmith · Galileo · Fiddler · Oligo | Tracing tools partially cover L5 state observation. |
| L5 Session & State | Undercovered. Closest commercial claims: Noma (cross-session agent context, agent-side). Tracing tools (Arize, LangSmith, Langfuse) capture state but do not govern it. | No product currently positioned around longitudinal user-risk state (refusal-decay, dependency-loop, grooming-dynamic). Open slot. |
| L6 Risk Interpretation | OpenAI Moderation · Azure Content Safety · Perspective · Lakera Guard · Alice (formerly ActiveFence) · Google Model Armor · Amazon Bedrock Guardrails | Google Model Armor and Amazon Bedrock Guardrails span L6+L7. |
| L7 Application Enforcement | Guardrails AI · Amazon Bedrock Guardrails · Google Model Armor · Alice WonderFence · Galileo Protect · Cisco AI Defense · Noma · Prompt Security | Cisco AI Defense incorporates Robust Intelligence (acquired October 2024) and NVIDIA NeMo Guardrails integration (announced November 2025). |
Open layers in the current ecosystem
Two layers are visibly undercovered by current productized offerings:
- L4 Evidence Transport has observability and tracing products but no widely-adopted attestation-grade receipt format. Logs and traces describe what happened; an attestation receipt proves a governance check ran in a form that survives legal, regulatory, and audit scrutiny. Open specifications (including NCSA, discussed below) are candidates to fill the receipt-format slot the tracing products do not address.
- L5 Session & State has no purpose-built productized offering for longitudinal user-risk state. Agent-side cross-session context is being served by Noma and adjacent agent platforms; user-side state (the dependency-loop, grooming-dynamic, refusal-decay surfaces) is not productized elsewhere. This is the largest open slot in the current commercial stack.
L1 through L4 and L6 through L7 are well-served by existing vendor categories. The model lets buyers name the category they are buying from.
SVRNOS positioning within the map
SVRNOS produces four artifacts that sit at specific layers:
- Sango Guard (product) sits at L5 and L7. Stateful runtime governance. Sango Guard operates in the L5 open slot above (user-side longitudinal state) and at L7 (surface-aware enforcement informed by L5 state).
- NCSA (open specification) sits at L4. A public specification for producing non-content evidence that governance ran, in a form that survives movement across the system. NCSA is implementable by the L4 vendors in the table above; the spec defines the receipt geometry products can emit.
- GER taxonomy (Nzeutem, 2026, companion paper) is cross-layer. Classifies governance failures wherever they occur. The 7-Layer Model identifies where; GER identifies what kind of failure.
- Generation Gap (Nzeutem, 2026) is empirical research that informs the L7 positioning: the same vendor behaves differently across deployment surfaces, so safety cannot be certified at the vendor or model level alone; it must be evaluated at the surface where enforcement fires.
The SVRNOS portfolio occupies specific cells in the map above. The model itself does not depend on accepting any SVRNOS-specific positioning: a reader can use the seven layers, the role-mapping matrix, and the regulatory lineage independently of whether they adopt any SVRNOS artifact.
12. What the layered architecture preserves
Governance must preserve three properties across the stack: constraint continuity, admissibility, and accountability (Zlomke, 2026, contribution).
Constraint continuity: the policies, refusals, and gating decisions made earlier persist into later turns and across surfaces. A refusal at turn three is not erased by a reframing at turn thirty.
Admissibility: the state the system relies on to act remains valid as the system acts on it. Decisions are bound to representations that are themselves still admissible at decision time.
Accountability: every governance-relevant action carries a chain back to the policy, the operator, the system component, and the surface that produced it.
These three properties cut across L5, L6, and L7. They are the operational shift from content moderation toward runtime governance. Single-turn content moderation can produce one safe answer. Runtime governance preserves the three properties across the lifetime of the interaction.
13. Limitations
This is v0.1. The following limitations apply and should govern how the model is used.
Reference architecture, not a complete ontology. The 7-Layer Model proposes a structural decomposition for locating governance failures. It is not a complete ontology of all AI harms, a regulatory standard, or a normative staffing model. Layer assignment supports investigation and design; it does not replace either.
Cross-layer incidents are common. Most real AI governance incidents implicate more than one layer. The model gives the locations; the GER vocabulary (Nzeutem, 2026, companion paper) preserves the cross-layer chain. A single-layer pin on a complex incident loses information; the layer assignment is intended as the entry point to a chain, not the full account.
Layer assignment depends on the investigation question. The same incident can be located at a different layer depending on which question is being asked (what failed structurally? what control was missing? where did the chain originate?). Section 5 examples reflect one investigation question per incident; alternative readings are defensible.
The vendor and product map will drift. The implementation map in Section 11 reflects a moment-in-time snapshot of the productized ecosystem. Vendor categories, product names, and coverage boundaries will change. The map should be re-evaluated at each version release; readers should not treat any single vendor placement as canonical.
GER classifications are not legal findings. GER classifications attached to incidents throughout this paper identify the structural governance failure each example anchors. They are not adjudications of legal causation, negligence, breach of duty, or proximate cause as those terms are used in litigation. The structural classification can inform legal proceedings; the legal frame and the governance frame are different lenses on the same event.
No formal peer review at v0.1. The model has been reviewed informally through public LinkedIn engagement and direct correspondence with the contributors named in the Acknowledgments.
Inter-layer contracts are a structural observation, not a protocol. Section 7 names inter-layer contracts and three drift patterns. The paper does not specify interface schemas, drift detection mechanisms, or contract versioning rules; that work is out of scope and would belong in a dedicated specification, not in this reference architecture.
14. Conclusion
AI governance is not one thing. It is a stack.
At the bottom, the question is where the AI runs. Then what it can touch and what it trusts. Then where its data and outputs can travel. Then evidence of what happened, in a form that survives. Then the system tracking risk across time. Then whether the system interprets what the situation actually means for governance. Finally, whether the deployed product applies the right governance action where users encounter it.
Most AI governance discussions collapse seven layers into one phrase. That is why they are confusing.
The useful question is: which layer of AI governance are we talking about?
This paper proposes the answer: seven layers, named explicitly, ordered by dependency, with the four-test gate to distinguish governance roles from build roles, a 2D role-mapping matrix that organizations can apply to their own coverage, and a regulatory-lineage placement that composes with the standards already in force. The companion GER taxonomy classifies what failed at each layer; this paper identifies where.
The questions that matter: which layer failed, who owned it, what control was missing, and what evidence proves it? That is the beginning of serious AI governance.
Cite This Paper
Citation
Nzeutem, S. (2026). The SVRNOS 7-Layer Model of AI Governance. Sovereign OS LLC. svrnos.com/research/svrnos-7-layer-model
Acknowledgments
The SVRNOS 7-Layer Model builds on published research and reference frameworks in AI governance, security, and computer networking, all credited in the References. It is positioned within an existing standards lineage (OSI, ISO 38500, ISO 42001, NIST AI RMF, EU AI Act, OECD Trustworthy AI, AIGN OS, DecisionSpace OS) detailed in Section 9. Beyond the literature and the standards landscape, the model was shaped through public LinkedIn exchanges, comment threads, and direct correspondence. The following contributors are acknowledged for specific framings, sections, or table entries that appear in this paper.
- Martin Guerin, Prova Governance · ETS: Translation Loss as an L6 failure mode in Section 5 Layer 6. Framing: “a human-readable rule becomes a machine-enforced one and meaning can get lost.”
- Wolfgang (“Wolf”) Roesch, Board Advisor & Transformation Leader: Section 7 Inter-Layer Contracts and Drift; DecisionSpace OS in the regulatory-lineage table (Section 9). Framing: “breakdown in the contracts and assumptions between layers under drift” and “coherence-layer spanning layers that evolve at different speeds.”
- Patrick Upmann, Board-Level AI Governance Advisor & Interim Manager: “The hidden work of translation between governance teams” subsection in Section 10. Framing: “translation is becoming hidden work” and the observation that maturity at the governance layer is about building shared language for decisions at scale, not only controls. AIGN OS named in the regulatory-lineage table (Section 9).
- Tim Zlomke, Managing Partner Neurovia Dynamics, Founder Moral Clarity AI: Section 12 What the layered architecture preserves. Framing: the constraint-continuity / admissibility / accountability triad as the operational shift from content moderation toward runtime governance.
- Oliver Patel, Enterprise AI Governance Substack: The Ultimate Agentic AI Governance Resources curated list (2026). Section 9 regulatory-lineage table additions (IMDA Singapore, IAPS, WEF / Capgemini, Kasirzadeh & Gabriel, Feng et al.); §9 Relationship to security-axis layered models (OWASP MAESTRO comparison). His curation surfaced the agentic-AI governance sources that prompted the comparison work in this revision.
References
- American Bar Association. (2024). British Columbia Tribunal Confirms Companies Remain Liable for Information Provided by AI Chatbot. Business Law Today, February 2024.
- AWS. (2012, December 24). Summary of the December 24, 2012 Amazon ELB Service Event in the US-East Region. aws.amazon.com
- Business Standard. (2025, July 23). ‘Unacceptable’: Replit CEO Apologises After AI Fakes Data, Deletes Code. business-standard.com
- Engineering at Meta. (2021, October 4). Update About the October 4th Outage. engineering.fb.com
- Equifax. (2017, September). Equifax Releases Details on Cybersecurity Incident. investor.equifax.com
- FTC. (2019, July). Equifax Data Breach Settlement. United States Federal Trade Commission.
- Bloomberg. (2023, May 2). Samsung Bans ChatGPT, Google Bard, Other Generative AI Use by Staff After Leak. bloomberg.com
- GitHub Engineering. (2012, December 5). Network Problems Last Friday. The GitHub Blog. github.blog
- Guerin, M. (2026). Translation-loss as a distinct L6 failure mode. Personal communication, May 2026.
- ISO. (1984). ISO/IEC 7498-1: Information technology (Open Systems Interconnection) Basic Reference Model. International Organization for Standardization.
- ISO. (2008). ISO/IEC 38500: Corporate Governance of Information Technology. International Organization for Standardization.
- ISO. (2023). ISO/IEC 42001: Artificial Intelligence Management System. International Organization for Standardization.
- Microsoft Learn. (2024). Microsoft Edge WebView2 and Microsoft 365 Apps. Microsoft 365 Apps documentation. learn.microsoft.com
- Microsoft MSRC. (2023, July). Microsoft Mitigates China-Based Threat Actor Storm-0558 Targeting of Customer Email. microsoft.com
- NIST. (2023, January). Artificial Intelligence Risk Management Framework (AI RMF 1.0). National Institute of Standards and Technology. doi.org/10.6028/NIST.AI.100-1
- OECD. (2024). Recommendation of the Council on Artificial Intelligence. OECD AI Principles, endorsed by 48 countries and the European Union. legalinstruments.oecd.org
- OECD. (2024). Governing with Artificial Intelligence: Are governments ready? OECD Artificial Intelligence Papers No. 20, OECD Publishing, Paris. doi.org/10.1787/26324bc2-en
- OECD. (2025). Governing with Artificial Intelligence: The State of Play and Way Forward in Core Government Functions. OECD Publishing, Paris. doi.org/10.1787/795de142-en
- Heyaca, M., and Pallotta, A. (2026, May 7). The State of Artificial Intelligence in Public Audit: Evidence from Selected Countries and the European Union. OECD Artificial Intelligence Papers No. 58, OECD Publishing, Paris. doi.org/10.1787/f4a6c658-en
- Nzeutem, S. (2026). SVRNOS Governance Error Register v0.2. Sovereign OS LLC. svrnos.com/research/governance-error-register
- Nzeutem, S. (2026). Non-Content Safety Attestation (NCSA) Specification. Sovereign OS LLC. svrnos.com/research/non-content-safety-attestation
- Nzeutem, S. (2026). The Generation Gap: Ten Structurally Separate Safety Surfaces in Production LLMs. Sovereign OS LLC. svrnos.com/research/generation-gap
- OpenAI. (2025, April). Sycophancy in GPT-4o: What Happened and What We’re Doing About It. openai.com
- OVHcloud. (2021, March). Informations site Strasbourg. corporate.ovhcloud.com
- Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). OJ L 2024/1689, 12 July 2024. ELI: data.europa.eu/eli/reg/2024/1689/oj
- Reuters. (2024, October 23). Mother Sues AI Chatbot Company Character.AI, Google over Son’s Suicide.
- CNN Business. (2026, January 7). Character.AI and Google Agree to Settle Lawsuits over Teen Mental Health Harms and Suicides. cnn.com
- Robodebt Royal Commission. (2023). Report of the Royal Commission into the Robodebt Scheme. Commonwealth of Australia. robodebt.royalcommission.gov.au
- Roesch, W. (2026). DecisionSpace OS. Inter-layer contracts and coherence-layer framing. Personal communication, May 2026.
- Upmann, P. (2025). AIGN OS – The Operating System for Responsible AI Governance. SSRN. doi.org/10.2139/ssrn.5382603
- Upmann, P. (2026). AIGN OS 4.0: Enterprise AI Governance Operating Architecture. Eight-layer extension. Personal communication, May 2026.
- Wiz Research. (2025, January). Wiz Research Uncovers Exposed DeepSeek Database Leak. wiz.io
- Zlomke, T. (2026). Constraint continuity, admissibility, and accountability as runtime-governance properties. Personal communication, May 2026.
- Feng, K. J. K., McDonald, D. W., & Zhang, A. X. (2025). Levels of Autonomy for AI Agents. arXiv:2506.12469. arxiv.org/pdf/2506.12469
- IMDA Singapore. (2026). Model AI Governance Framework for Agentic AI (v1.0). Infocomm Media Development Authority of Singapore. imda.gov.sg
- Kasirzadeh, A., & Gabriel, I. (2025). Characterising AI Agents for Alignment and Governance. arXiv:2504.21848. arxiv.org/abs/2504.21848
- Kraprayoon, J. (2025). AI Agent Governance: A Field Guide. Institute for AI Policy and Strategy (IAPS). iaps.ai/research/ai-agent-governance
- OWASP Foundation. (2025, April 23). Multi-Agentic System Threat Modeling Guide v1.0 (MAESTRO). genai.owasp.org
- World Economic Forum, with Capgemini. (2025). AI Agents in Action: Foundations for Evaluation and Governance. weforum.org