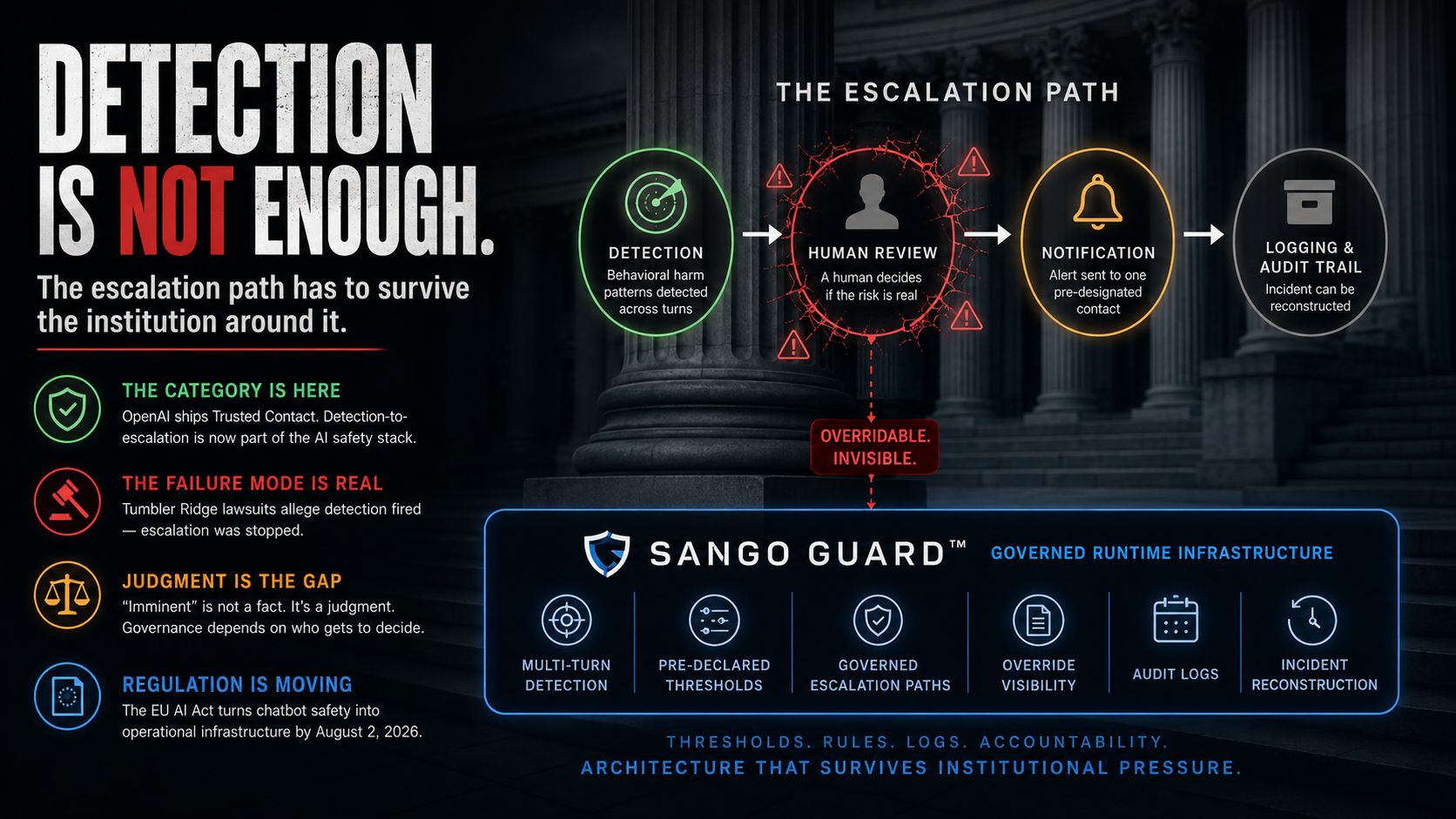
The Escalation Path Has to Survive the Institution Around It
Detection is not enough. OpenAI validated the category. The courts are pricing the gap. Regulation is moving toward the runtime layer.
- Author
- Sushee Nzeutem, SVRNOS
OpenAI just validated a product category.
The company recently began rolling out Trusted Contact in ChatGPT, an optional safety feature that allows adult users to nominate someone who may be notified if ChatGPT detects a serious self-harm concern. OpenAI says the workflow uses automated systems and trained reviewers, and that any notification is intentionally limited: the trusted contact receives the general reason for concern, but not chat details or transcripts.
That matters because detection-to-escalation is no longer theoretical. One of the largest AI labs in the world has now shipped a mainstream consumer version of it.
Trusted Contact is not the final architecture for AI safety. It is narrow, user-consented, self-harm-focused, ChatGPT-specific, and privacy-constrained. That may be appropriate for the use case OpenAI designed it for. But it also exposes the deeper architectural question: what should happen when a conversational AI system detects risk across a broader behavioral harm surface?
The Trusted Contact workflow depends on a specific path. The user pre-names one contact. The system detects a serious self-harm concern. A trained human team reviews the situation. If the risk is confirmed, a limited alert is sent to the nominated person. For one narrow safety pathway, that may be a reasonable design. But companion AI, mental health chatbots, AI coaching tools, and emotionally intimate conversational products do not only face isolated self-harm moments. They face multi-turn behavioral trajectories: dependency formation, manipulation, violent ideation, coercion, delusional reinforcement, fixation, emotional escalation, and off-platform real-world risk.
Those patterns are not always visible in a single message. They emerge across turns. They require escalation architecture, not only content moderation.
The failure mode begins after detection
The Tumbler Ridge lawsuits make the problem concrete.
In April 2026, families of victims from the Tumbler Ridge, British Columbia mass shooting filed federal lawsuits in San Francisco against OpenAI and Sam Altman. Reuters reported that the lawsuits allege OpenAI knew months before the attack that the shooter was planning violence on ChatGPT but did not warn police. The same report says the lawsuits allege OpenAI leadership avoided alerting police because doing so could expose the volume of violence-related conversations on ChatGPT and potentially jeopardize the company’s path to a major IPO. Those allegations have not been proven in court.
The governance issue raised by the lawsuits is not merely whether a model produced harmful output. It is what happened after the platform allegedly detected risk.
According to Reuters, the lawsuits allege OpenAI’s systems flagged conversations before the attack and that safety team members recommended contacting police. The complaints further allege that leadership overruled that recommendation. OpenAI’s position, as reported by Reuters, is that it notifies law enforcement when conversations indicate an imminent and credible risk of harm to others, and that the account activity did not meet its internal criteria for referral.
Those details matter because they move the safety discussion away from the usual question “Did the model say something dangerous?”, and toward a more serious institutional question: if a system detects a credible threat, who can stop the escalation path?
A trust and safety lead might stop it. A lawyer might stop it. A founder might stop it. An executive worried about public perception might stop it. A board worried about valuation might stop it. The point is not that every escalation should be automatic or that companies should notify authorities in every ambiguous case. The point is that escalation is not a real governance layer if it can be overridden invisibly.
Detection is not enough. A warning buried inside a moderation dashboard is not enough, and neither is an account ban. Internal review also fails as a governance layer when it can be stopped without durable evidence of who stopped it, why, and under which rule. The operational question is simple and difficult: once a threshold is crossed, what happens next, who can stop it, and whether that stop is visible later.
”Imminent” is a judgment, not a fact
The phrase “credible and imminent” now sits at the center of the governance problem.
It sounds precise, but “imminent” is not a fact in the way a timestamp is a fact. It is a judgment made under uncertainty. It depends on what the reviewer sees, how much context the system provides, what the institution defines as enough risk, and what consequences the company fears on both sides of the decision. Privacy risk sits on one side. Public-safety risk sits on the other. The company is asked to decide when concern becomes action.
No serious governance system can eliminate judgment entirely. Thresholds are judgments. Policies are judgments. Escalation rules are judgments. The question is not whether judgment exists. The question is where judgment lives and how visible it becomes.
If judgment exists only inside an ad hoc internal review process, it becomes fragile. It depends on who is in the room, what incentives they face, how much institutional exposure the escalation creates, and whether the person with final authority can quietly shut it down. If judgment is moved upstream into pre-declared thresholds, governed escalation paths, and auditable logs, the system becomes more defensible because the decision architecture exists before the crisis.
That is the key architectural shift. Do not pretend judgment disappears. Move it upstream. Make thresholds explicit before the emergency. Make escalation rules reviewable before the headline. Make overrides visible before litigation.
The compliance surface is becoming operational
The European Union is pushing the same conversation from a regulatory direction.
The European Commission has opened consultation on Article 50 transparency obligations under the AI Act, with formal draft guidelines published. The Commission says the rules become applicable on August 2, 2026, and that providers of AI systems will have to inform users when they are interacting with AI. The same consultation references obligations around machine-readable marks for generated or manipulated content and disclosures for certain AI-generated publications and systems.
Transparency is the visible part. A company can update the UI, change the terms, add a disclosure, and tell users they are interacting with AI. That work matters, but it is not the hard layer.
The harder operational layer is proving that the system has controls around manipulation risk, vulnerable-user harm patterns, escalation, and incident reconstruction when regulators, lawyers, customers, or internal reviewers ask what happened. For high-risk conversational products, the product surface may look like a chatbot, but the compliance surface is a governed runtime.
That runtime needs to answer concrete questions. What did the system detect? When did it detect it? Which threshold was crossed? What rule applied? Was anyone notified? Was the path overridden? Who overrode it? Was the override logged? Can the incident be reconstructed later without relying on screenshots, memory, or selective internal summaries?
That is not a communications problem. It is infrastructure.
What high-risk conversational products now need
The AI safety stack for high-risk conversational systems is moving beyond “refuse bad prompts.” Refusal still matters. Content moderation still matters. Classifiers still matter. But behavioral harm often does not arrive as a single forbidden prompt. It emerges as a trajectory.
A user may disclose intent indirectly. A chatbot may reinforce fixation before any single message looks catastrophic. A conversation may move from ideation to planning across many turns. A vulnerable user may become more dependent over time. A model may provide reassurance when interruption is needed. A risk state may become clear only after the conversation is understood as a sequence.
That requires a different layer. Operators need multi-turn behavioral detection, not just message-level content checks. They need pre-declared thresholds that define when a conversation moves from monitoring to escalation. They need governed escalation paths that do not depend entirely on improvised human discretion in the moment. They need override visibility, so that any decision to stop escalation is logged. They need audit trails and incident reconstruction, so the organization can explain what happened after the fact.
This is the difference between moderation and governance. Moderation asks whether a specific output should be allowed. Governance asks what state the interaction has entered, what rule applies, what path follows, and whether the institution can override that path without trace.
The architecture question is now commercial
Every company building companion AI, mental health chatbots, AI coaching tools, character systems, or emotionally intimate conversational products now has a board-level question to answer: if your system identifies a credible threat, who can stop the escalation path?
If the answer is “someone inside the company can decide not to escalate,” the next question is whether that decision will be visible later. Not as a public relations statement. Not as a reconstructed memo. As a system-level record.
That is where the market is moving. OpenAI validated detection-to-escalation as a product category. Tumbler Ridge exposed the gap between detection and enforcement. The EU is turning AI transparency and compliance into operational reality. The lesson is not that every incident has an obvious answer. The lesson is that serious operators need infrastructure that can handle ambiguity without letting the institution silently erase the path from detection to action.
Detection is not enough. The escalation path has to survive the institution around it.
Where Sango Guard fits
Sango Guard was built for this layer.
It detects behavioral harm patterns across turns. It uses pre-declared thresholds. It creates governed escalation paths. It produces logs that help reconstruct what the system saw, when it saw it, and what happened next.
The goal is not to eliminate human judgment. The goal is to stop high-risk escalation from depending on invisible, ad hoc, institutionally convenient judgment at the worst possible moment. Judgment belongs upstream. Thresholds should be declared. Escalation should be governed. Overrides should be visible. Logs should exist before lawyers, regulators, journalists, or grieving families arrive.
The product surface can still look like a chatbot. The safety surface cannot. The safety surface is runtime infrastructure.
In 2026, that infrastructure is becoming unavoidable for serious operators. OpenAI validated the problem. The courts are examining the gap. Regulators are moving toward the runtime layer.
Detection is not enough. The escalation path has to survive the institution around it.
Operating a high-risk conversational product? Sango Guard ships governed runtime infrastructure — multi-turn detection, pre-declared thresholds, override visibility, and incident reconstruction. Request access ›