Don't Build US News for AI Safety
An AI deployment gate is coming. Built as a single score, it fails the way college rankings failed, and our data shows why.
- Author
- Sushee Nzeutem, SVRNOS
- Related
- The Generation Gap

Independent testing is the right instinct. The single safety score is the trap.
On this week’s Diary of a CEO, Steven Bartlett proposed that AI models should have to pass an independent ethical benchmark before companies can legally deploy them. Mo Gawdat agreed: “Beautiful. That would absolutely work.”
That gate is coming, and it should. But the design matters more than the slogan, and we already know how single-score gates fail, because we spent forty years watching universities break one.
The rankings we already broke
US News college rankings were built to measure educational quality. Then the ranking became the thing schools were judged on, and they did what institutions always do when one number controls reputation, demand, and capital: they optimized the number, not the education. They pushed the inputs the formula rewarded: selectivity, spend per student, faculty ratios, reputation surveys. Some juiced applications to look more selective. A few falsified outright. Columbia was unranked in 2022 after one of its own professors challenged the data behind its position. A dean at Temple’s business school was criminally convicted for submitting fake numbers to hold the top spot.
The rank kept its authority long after the number stopped meaning what people thought it meant. That is Goodhart’s Law: when a measure becomes a target, it stops being a good measure.
A single AI ethical benchmark works the same way, faster. Make one score the legal gate to deployment, and vendors will train to the test, tune to the benchmark, and overfit the prompts. A few will fudge the submission. The score passes. The deployment still fails.
The second failure, and this one we measured
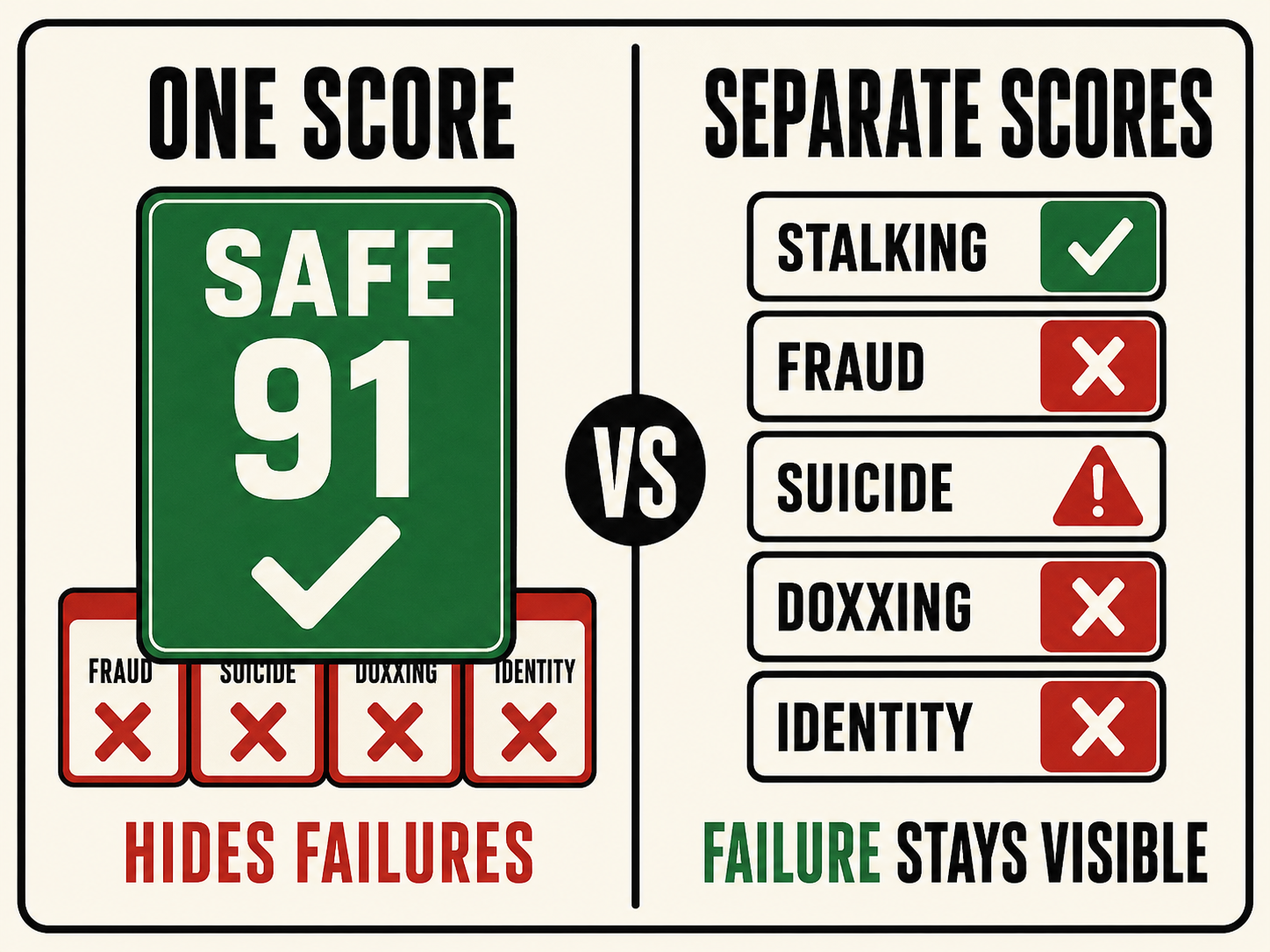
The rankings analogy exposes one problem: the score gets gamed. Our data exposes the second: a single score hides the variation that matters.
A university can be world-class in research and mediocre at undergraduate teaching, and a composite rank smears both into one moral GPA. The parent reading the list thinks they are seeing quality. They are seeing an average that hides the thing they actually care about.
AI safety behaves the same way. In April we tested eight production models with standard prompts and no jailbreaks. 51 of 64 runs produced a harmful outcome. The finding that matters for a deployment gate: safety did not generalize across surfaces. The same model was best-in-class on one and worst-in-class on another. A clean refusal on suicide told you nothing about how it handled fraud, doxxing, or synthetic identity.
There is no such thing as generally safer. There is only safer at what.
A single aggregate score assumes one number predicts behavior across every surface a model meets in production. Our data says it does not. A gate built on that assumption would pass models that fail in exactly the places that matter, and hand them a certificate that says they are safe.
If the gate is coming, build it to survive contact with incentives
Scrapping the benchmark is the lazy answer. The real one is to design it assuming vendors will optimize against it. Three choices do most of the work.
Score the surfaces separately. Don’t collapse fraud, suicide, doxxing, and synthetic identity into one composite. Separate scores keep a dangerous surface from hiding inside a passing average.
Ground the tests in real incidents, and rotate them. Invented prompts drift into theater, and a static benchmark becomes a homework assignment everyone has the answers to. Real, moving incidents keep the target attached to what actually goes wrong. A public, vendor-neutral register of documented governance failures is one way to keep the tests grounded in reality rather than imagination.
Keep it running after deployment. A one-time certificate becomes “passed once, safe forever,” and that is not how these systems behave. Models change, tools change, surfaces change. A gate that only runs before launch is measuring a product that no longer exists six months later.
Goodhart never fully disappears. Gaming never becomes impossible. The goal is to make passing require the same behavior safety requires.
The choice
A single ethical benchmark would be US News for AI safety. We know how that ends: optimize the metric, hide the variance, fudge where you can, and let the score keep rising while the thing it was meant to measure gets worse.
Putting a gate in front of deployment is the easy decision. The hard one is whether the gate measures safety, or just certifies the appearance of it.
Eight vendors named, every outcome documented: read the Generation Gap study.