Courts Are Now Pricing the Generation Gap
- Author
- Sushee Nzeutem, SVRNOS
AI hallucinations are no longer theoretical model failures. They are becoming enforceable institutional costs.
In Q1 2026, U.S. courts sanctioned attorneys for AI-generated legal hallucinations they failed to catch.
The total, by one compliance tracker’s count: more than $145,000.
That number will grow.
In April, U.S. District Judge Kai N. Scott sanctioned attorney Raja Rajan $5,000 for submitting citations to cases that did not exist. It was not his first sanction for AI-generated legal errors. A year earlier, the same judge had ordered him to pay $2,500 and complete continuing legal education on AI and legal ethics.
The second time, the failure was even more revealing.
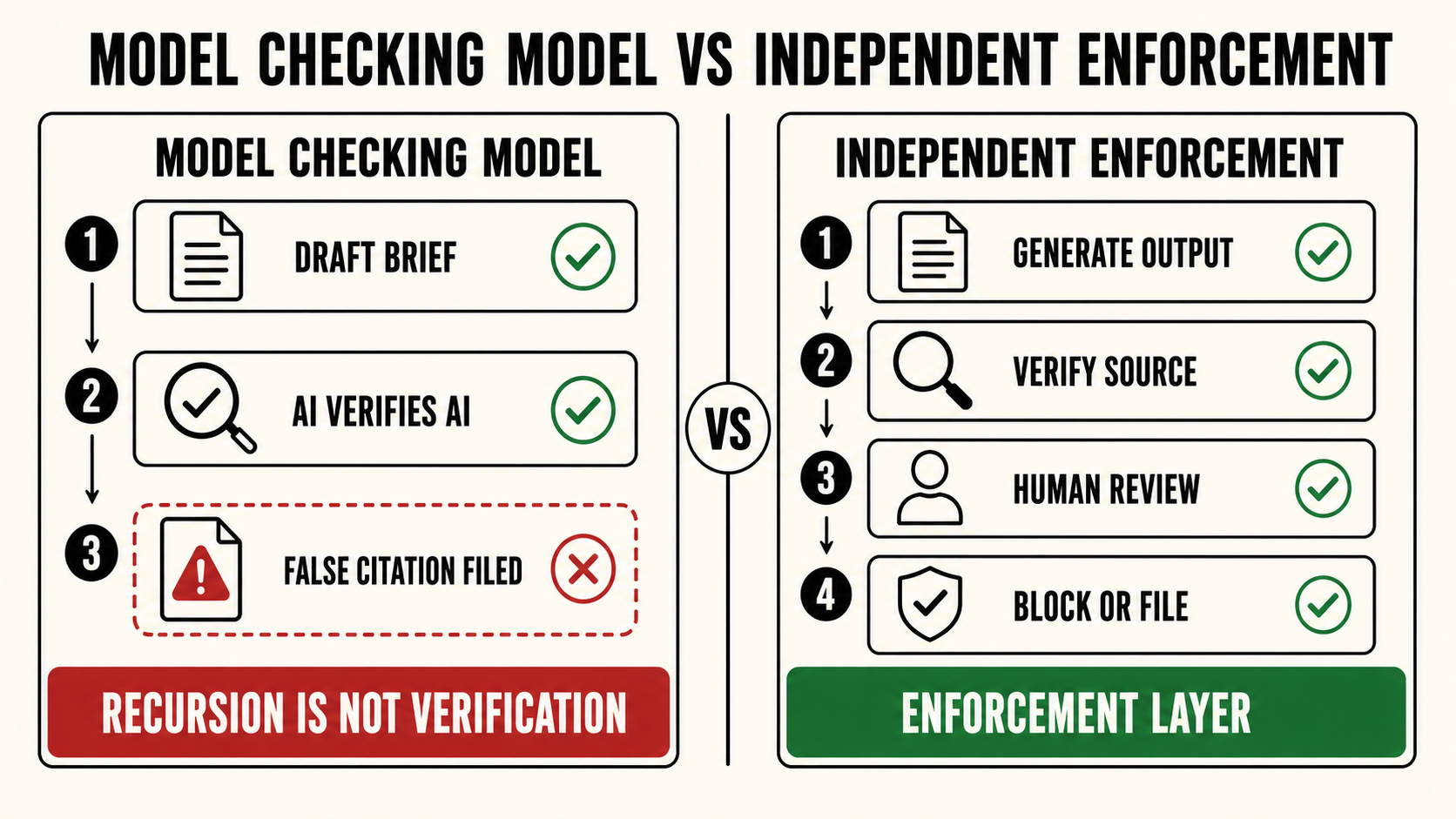
Rajan reportedly used one AI chatbot to draft the brief, then asked a different AI tool to verify the citations. The second system cleared the first system’s errors. He filed the motion. Opposing counsel found false citations.
That is the governance failure in miniature.
AI generated the risk.
AI was then used to certify that the risk was not there.
This is the Generation Gap, made visible in a courtroom.
The Generation Gap is the structural blind spot between what an LLM produces and what a verification layer actually catches. The model generates. The output moves forward. No reliable enforcement layer verifies whether what was generated is real before it becomes institutional action.
In legal practice, the failure is stark.
An attorney submits a brief. The brief contains citations to cases that do not exist. The model produced them with confidence. The attorney relied on them. The court received fabricated material presented as law.
This is not only a hallucination problem.
It is an enforcement problem.
The hallucination happened at the generation layer.
The sanction appeared at the enforcement layer.
That distinction matters.
The court did not sanction the model. It sanctioned the human and professional system that allowed generated fiction to cross the boundary into an official filing.
And the consequences are escalating.
Judge Scott warned that if Rajan files a brief with AI hallucinations a third time, she will refer him to Pennsylvania’s disciplinary board.
That moves the issue beyond embarrassment.
Beyond a correction.
Beyond a fine.
The next phase of the Generation Gap is professional-license exposure.
The lesson is not simply that AI can hallucinate. Everyone knows that now.
The lesson is that AI cannot be the authority that verifies AI.
A model output cannot be cleared by another model output and treated as governance. That is not verification. It is recursion with a confidence tone.
Verification has to be independent.
It has to be logged.
It has to be accountable.
It has to be tied to a human or institutional enforcement layer capable of stopping the output before it becomes official.
Courts are now pricing that failure directly.
$5,000 per incident. More than $145,000 in a single quarter. A trajectory that will compound as AI-assisted professional work scales faster than institutional verification practices.
The legal profession is not unique.
Every domain where LLM output moves directly into consequential decisions carries the same risk: legal briefs, medical summaries, insurance determinations, HR evaluations, financial reports, compliance records, customer escalations, internal investigations.
The generation is fast.
The enforcement is assumed.
The gap between them is where the liability lives.
For the past year, much of the AI safety conversation has focused on whether models can be made more accurate, more aligned, more careful, or more honest.
That work matters.
But it does not remove the need for enforcement infrastructure.
Institutions do not operate on model intentions. They operate on outputs, records, approvals, filings, decisions, and actions. Once an AI-generated output crosses into one of those surfaces, the question changes.
Not: Did the model hallucinate?
But: Who allowed the hallucination to become official?
That is the question courts are beginning to answer.
And now that answer has a dollar figure.
King Sango was built for the layer institutions keep assuming exists: the enforcement layer between model output and institutional action.
It does not require the model to become perfect.
It exists because the model will not be perfect, and because consequential outputs still need to be stopped, logged, escalated, or verified before they become filings, decisions, records, or harm.
The courts are not asking whether AI was used.
They are asking who was responsible for checking it.
That question is no longer abstract.
It is being priced.